
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - Want the oppurtunity to discuss enhancements to PTC products? Join a working group! X
- Community
- PLM
- Windchill Tips
- Part II Enhancements on Windows Explorer Integrati...
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Notify Moderator
Part II Enhancements on Windows Explorer Integration for Windchill Desktop Integration 10.2
No ratings
In my last blog post Productivity Enhancements on Windows Explorer Integration for Windchill Desktop Integration 10.2, Part I I discussed the possibilities and enhancements around the Windchill Documents system folder in the Windows Explorer.
This blog will show you how easy it is to display Windchill Meta data information in the Windows Explorer Integration.
I will also discuss the integrated Windchill search and how leverage the Windchill Index Search functionality.
View Windchill Information
Windchill metadata information of your documents can be displayed in the Windows Explorer without opening a browser to access the Windchill web application. Even applying filters is possible.
To do so, you have to navigate from the Windchill Documents node to the context that you are interested. On the right hand pane you will see the stored documents.
You may add or remove attributes by right-clicking a Windows Explorer column heading to see a drop down menu of additional columns available.
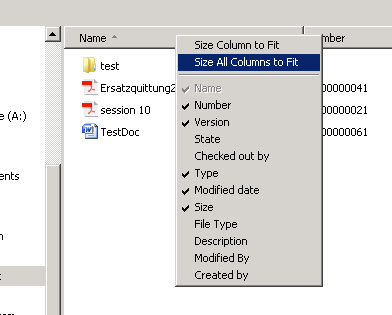
Is the attribute still not available in the out of the box list?
No problem, since Windchill 10.2 F000 you can select Windchill folder views to add columns that appear in the list. With Windchill 10.2 M010 even the filters on these views will affect the data displayed in the object list.
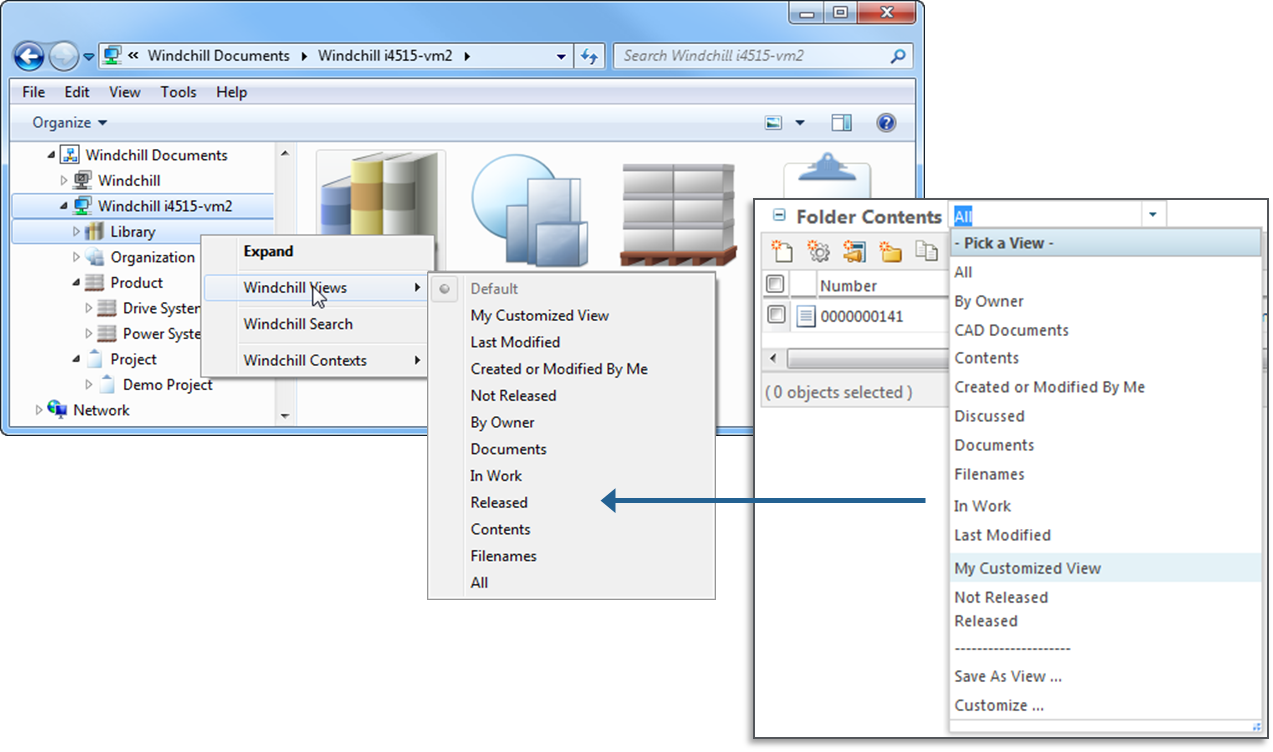
This allows you to configure which documents will be show in the folder. E.g. if you only want to display the latest document version, then apply filter settings on the Windchill table view (in the Set Filter step select Revision and Version attributes and set them to Latest).
Folder Search for Windows Explorer
All the features that I showed until now required that you exactly know where the documents are located in your Windchill system but this unfortunately is not always the case. While manual navigating through the folder structure is cumbersome and annoying to find a document, there is a simpler way to find your documents.
Starting in Windchill PDM Link 10.2 F000 you can search for any Windchill document using the Windchill Search action. This is a quick and easy way to search for your documents inside of the Windows Explorer Integration without the need to open the Windchill web application.
The search can be initiated from context, container or folder level within the Windchill Documents node. This will allow you to search by Name or Number on this context level and all sub-contexts.
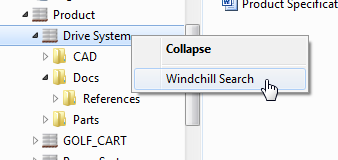
Please note that the search is case-insensitive and wildcards are allowed. Add asterisk (*) as a wildcard character to indicate that one or more characters can appear in that position.
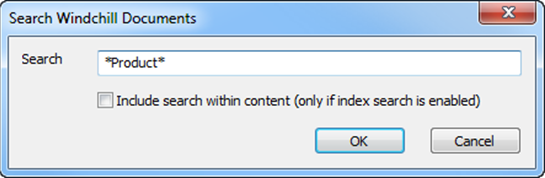
For Windchill systems with Index Search enabled, even document content will be taken into account when calculating the results if the option “Include search within content (only if index search is enabled)” is selected.
The native Windows Explorer search field (in the top right corner of the Windows Explorer) can also be used to perform a search but this will yield slightly different results. The search will only be performed on the current folder / context and not on any sub-context.
In case you are also interested in the location of document in the folder structure, you can use the right mouse button menu to select “Open File Location”. This will open the Windchill context or folder in which the object is stored.
Conclusion
This was the last part of my post about productivity enhancements on Windows Explorer Integration.
I hope that you liked this brief tour on the Windows Explorer Integration if you are interested in more details, you’ll find further information in the Windchill Help Center.
Thank you also for your many comments on part I.
As always let me and the community here about your thoughts and questions:
-
What do you like about the Windows Explorer Integration and what do you think is missing?
-
In which scenarios you are using the Windchill Explorer Integration?
-
…
Comments
Sep 22, 2015
09:21 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 22, 2015
09:21 AM
Thanks for this post. I run exactly many times into this problem, that PTC recommends to set the query limits to e.g. in the performance case https://support.ptc.com/appserver/cs/view/solution.jsp?source=subscription&n=CS153338
So all the default schedule jobs don't work anymore. This is just a little bit weird to have recommendations to limit the queries but on the other side some schedule jobs don't work anymore. I know that I can rewrite these jobs, but it would be great to have PTC done that for all customer. For me it wouldn't be a problem to have two different jobs: One with query limits and one without.
Thanks and regards
Björn
Sep 22, 2015
01:54 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 22, 2015
01:54 PM
Hello Björn and thanks for your post.
I'm not 100% certain what your concerns are, but you appear to be asking for the WVS Scheduler code to explicitly set the wt.pom.queryLimit before executing the method... this is not technically possible, I'm afraid.
The Performance / Runtime article CS153338 you mention does not explicitly instruct you to set the wt.pom.queryLimit and this is something that is very difficult to be precise about without a clear understanding of all the variables that might affect the maximum query size, but does make recommendations; whereas WVS article CS124149 is advising you to increase this limit to allow particularly large contexts to be processed by a WVS Scheduler method, without providing any specific guidance regarding the value you should set.
One thing is clear, if setting the queryLimit up to ~500,000 still does not allow the code to execute and / or you need to set it to -1 so there is no limit, then there is an argument to request performance optimization of the implicated scheduler code. If this is the case, I'd recommend you open a Windchill Performance case to have this code reviewed for optimization.
Sep 22, 2015
06:35 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 22, 2015
06:35 PM
Bjorn,
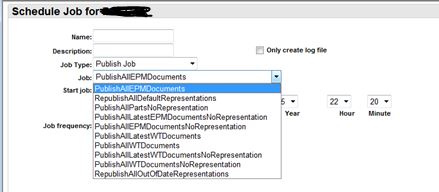
One of the main reasons for this article is to provide a solution to publish from a list of objects. The ability to publish the defaults as shown in the picture below should remain in tact as additional options. (these don't work for us!)
I'm hoping the process Gary has outlined can be an option for every company that is trying to generate lightweight images. Basic steps:
- Search for the objects or utilize the power of a queryreport.
- Take this list of objects found and send them to the publisher for generation of lightweight images.
Sep 23, 2015
02:43 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 23, 2015
02:43 AM
Hi Gary
Thanks for the reply. I just wanted to know the other user, that this is common problem. When you're coding such jobs, you have to know the amount of the possible process objects. Otherwise the job doesn't work.
Most customers which has a global setup it's not that easy just to reset the query limits. A Windchill restart is not possible so you should have the possibilities to run also the standard jobs without having switching this limit in the property files.
I do like your post and I'm hoping that's not you last one!
Thanks
Björn
Sep 23, 2015
08:37 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 23, 2015
08:37 AM
Bill Ryan,
One of the main reasons for this article is to provide a solution to publish from a list of objects.
That might be the reason, but the actual solution was never provided. Gary Jackson said, (emphasis mine)
One approach, that allows you to be in complete control over what is and is not published, is to create a custom method that simply processes a list of OID's from a text file you created. With basic Windchill customization skills, this should not be difficult to implement...
He clearly states at the end that an actual solution has not been provided:
... maybe one of you has already achieved this and is willing to share the code here...
There has been lot's of talk about the theoretical program flow, but nothing has actually been provided (by PTC or anyone else) that will DO it. We don't have Java programmers or any type of customization. We really need someone who understands Java and the Windchill API to build this, or at least provide a working example that we can tweak.
Also, Steps 2 and 3 seem overly complicated. If I'm going to extract the OID's from the database manually, why put that data back into Windchill as a WTDoc, just to need to re-locate it and parse it. Seems like it'd be much easier to simply drop a text file on disk somewhere and let the custom scheduler read that. (But, I'm no Java programmer!)
Sep 23, 2015
09:03 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 23, 2015
09:03 AM
Tom,
You are correct, this is not a solution but rather a recommended approach but one I discussed and ratified with the help of the WVS Product Owner, in order to confirm it's validity.
Like you. I am no Java programmer nor Windchill customization engineer and I was unable to source within PTC sample code for a scheduler method that already performs the task of reading the input file and processing its contents. I am, however, in discussion with a Tech Support colleague who is a Java programmer and is dabbling in Windchill customization; we are looking to see how much effort it would take to provide a sample method that you might then use as a basis for your implementation.
Regarding steps 2 and 3, the purpose was to support the use case where an admin user does not have access to the Windchill server (an all too common situation with secure Windchill implementations these days). By making the scheduler method get the file input from a WTDoc, we then allow a Windchill admin to upload the file on the WTDoc from their client mchine prior to executing the scheduler method on the server.
To be honest, if you were going to take the input from a file directly from the Windchill server's file system, a WVS Scheduler method is not the way to go and I would instead have recommended a command-line utility that could be executed directly on the server.
Sep 23, 2015
09:21 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 23, 2015
09:21 AM
To be honest, if you were going to take the input from a file directly from the Windchill server's file system, a WVS Scheduler method is not the way to go and I would instead have recommended a command-line utility that could be executed directly on the server.
Does such a utility exist, or would that have to be custom coded as well?
Thanks!
Sep 23, 2015
09:31 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Sep 23, 2015
09:31 AM
If this is a common requirement, then someone somewhere will have written such a utility but I've looked within PTC for such a sample and have not found one yet. As I mentioned, however, we are looking to provide sample code, along the lines of the approach I mentioned, that you could use but this may not be available in immediately.
You might want to contact PTC Global Services if this is something that you would like assistance with... it's possible that they have a library customization that they can provide but this is unlikely to be free.
Oct 02, 2015
10:32 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
10:32 AM
I think this article https://support.ptc.com/appserver/cs/view/solution.jsp?source=subscription&n=CS211115 is related to this blog.
Oct 02, 2015
11:59 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
11:59 AM
Hi Marco,
It is indeed and is in the references.
I am also working on another article with a customization engineer that will respond to the need that Tom and Bill have highlighted earlier.
Gary
Oct 02, 2015
12:03 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
12:03 PM
Hi Gary,
sorry for my previous comment.
I saw today this document on the daily mail from TS as new.
Oct 02, 2015
12:07 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
12:07 PM
Tech support has a problem with their knowledge base system where every time an article is change and re-released it shows up as "new" instead of "updated". The vast majority of articles that come out every day marked as "new" really aren't.
Oct 02, 2015
12:14 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
12:14 PM
Yes Tom,
I know this issue and I have also participated in a discussion with you and other users about it, I think with @jzupfer also involved.
Oct 02, 2015
12:45 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
12:45 PM
Hello, Tom and Marco,
I'm happy to share your experience with the knowledge base with my colleague in Technical Support; if they have an updated status, I'll share it here.
Thanks,
Jane
Oct 02, 2015
12:51 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
12:51 PM
Sorry Marco Tosin, I had forgotten you were in on that conversation. Jane Zupfer, here is the conversation being referred to: Re: Windchill 10.3 (X-26)
Oct 02, 2015
12:55 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
12:55 PM
Don't worry Tom,
I've cited the wrong person 
Oct 02, 2015
12:57 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
12:57 PM
I noticed today that John Deere has already developed the ability to publish from a CSV. See page 15 from their PTC Live Global 2013 presentation.

Maybe someone on the community who knows John Deere can see if they might be willing to share this code.
Oct 02, 2015
01:15 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 02, 2015
01:15 PM
Thanks! I see that you're already talking with Heidi, so you're in great hands. I did, however, send an email asking for any status update, so if I get information about availability of a fix, I'll respond on this thread.
Oct 08, 2015
03:54 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 08, 2015
03:54 PM
As the eagle eyed Tom Uminn has spotted already, we've updated Article CS211115 with details of a new custom scheduler method Publish_EPMDoc_WithCSVFile and related command-line PublishUtilreadCSV utility that will read EPMDoc OID's from a "||" separated CSV file and create a Publish Job to create a fresh default Representation for each one.
A big thanks must go to my colleague YSH in South Korea for responding to this request so efficiently and he even agrees to field any questions you may have regarding this sample custom code that we hope will help solve some of your trickiest republishing needs; just respond to this community thread and I will either respond myself or pass them on to him.
Regards,
Gary
Oct 08, 2015
05:28 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 08, 2015
05:28 PM
Gary, may need some clarification on these two lines from the document:
Line 1) - by forcing the republishing for existing default representations, or not
Line 2) - Note: The Publish_EPMDoc_WithCSVFile schedule method deletes the existing Representation (along with any Annotation Sets) before publishing a new Representation
What happens if I'm NOT forcing the republishing of existing default representations and using the publish_epmdoc_withcsvfile function? I don't want to lose annotation sets on assemblies that are already published with a default representation. Do I need to make sure assemlbies with a default representation are not inlcuded in the CSV file for this scenario?
Oct 08, 2015
05:43 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 08, 2015
05:43 PM
One more note...is it possible to have an "included" list of Contexts instead of an "excluded"? We have over 500 contexts. Maybe it's as easy as changing the text from excluded to included.
wvs.jobs.publishFilter.excludedContextNameForPublication=PRODUCT3,LIBRARY1
Oct 09, 2015
07:12 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 09, 2015
07:12 AM
Bill Ryan wrote:
Gary, may need some clarification on these two lines from the document:
Line 1) - by forcing the republishing for existing default representations, or not
Line 2) - Note: The Publish_EPMDoc_WithCSVFile schedule method deletes the existing Representation (along with any Annotation Sets) before publishing a new Representation
What happens if I'm NOT forcing the republishing of existing default representations and using the publish_epmdoc_withcsvfile function? I don't want to lose annotation sets on assemblies that are already published with a default representation. Do I need to make sure assemlbies with a default representation are not inlcuded in the CSV file for this scenario?
This is YSH's response:
Publish_EPMDoc_WithCSVFile UI scheduler method only use wvs.jobs.publishFilter.withCSV parameter and do not get any other parameter value in additionalEPMDocJobs.properties. It is hard-corded in AdditionalEPMDocJobs.java source as below.
AdditionalEPMDocJobs.java source 794 ~ 814 lines:
----------------------------------------------------------------------------------------------8<-----------------------------------------------------------------------------------------------------------------------------
/**
* Attempts to publish a Representable generating a Representation
*
* @param viewableLink If true and the data has already been published, the viewable data will be passed back to allow access by getViewableLink
* @param forceRepublish Overwrites an existing representation should one already exist
* @param objectReference Reference of the Representable to be published
* @param configReference Reference of the EPM Config Spec, if null, latest is used.
* @param partConfigReference Reference of the Part Config Spec, if null, latest is used.
* @param defaultRep Should the created representation be the default or not. The first representation in always default.
* @param repName Name of The representation to be created
* @param repDescription Description of the representation to be created
* @param structureType The type of structure walk to be performed
* @param actionString string representation of the action XML file contents
* @param jobSource int of source that submitted the job, 0=unknown, 1=manual, 2=checkin, 3=schedule
*
* @return boolean true if successful
*
public boolean doPublish(boolean viewableLink, boolean forceRepublish, String objectReference, String configReference, String partConfigReference,
boolean defaultRep, String repName, String repDescription, int structureType, String actionString, int jobSource)
**/
result = pub.doPublish(false, true, objRef, (ConfigSpec) null, (ConfigSpec) null, true, null, null,
Publisher.EPM, null, 3);
----------------------------------------------------------------------------------------------8<-----------------------------------------------------------------------------------------------------------------------------
Publish_EPMDoc_WithCSVFile UI scheduler method is hard-coded with below values:
viewableLink : false
forceRepublish : true
objectReference: Retrieved from CVS file
configReference: null
partConfigReference: null
defaultRep: true
repName: null
repDescription : null
structureType: Publisher.EPM
jobSource: 3
And,
Publish_EPMDoc_WithCSVFile schedule method will delete the existing Representation (along with any Annotation Sets) before publishing a new Representation. It will remove previously published Representation and it’s annotation. Both Representation and it’s Annotation should be removed together.
If customer comments out below lines in AdditionalEPMDocJobs.java source (787 ~ 791 lines). Then, the Publish_EPMDoc_WithCSVFile schedule method will force republish the CAD model and will not remove previously created Representation and its annotation set. i.e. Customer will see 2 Representation in the CAD Document.
Comment out these line in AdditionalEPMDocJobs.java source (787 ~ 791 lines):
/**
try {
deleteRepresentation(epm);
} catch (WTException e) {
throw e;
}
**/
Force to republish Result: 2 Representations

Oct 09, 2015
07:21 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 09, 2015
07:21 AM
Bill Ryan wrote:
One more note...is it possible to have an "included" list of Contexts instead of an "excluded"? We have over 500 contexts. Maybe it's as easy as changing the text from excluded to included.
wvs.jobs.publishFilter.excludedContextNameForPublication=PRODUCT3,LIBRARY1
YSH's Response:
Below lines (286 ~ 299 lines) in AdditionalEPMDocJobs.java source. If customer change SearchCondition.NOT_EQUAL to be SearchCondition.EQUAL, then it will have an "included" list of Contexts instead of an "excluded"
-----------------------------------------------8<------------------------------------------------
// excluded context from publication
String[] excludedContextNameForPublication = getjobsprops.getExcludedContextNameForPublication();
if (excludedContextNameForPublication != null){
for (int i=0; i<excludedContextNameForPublication.length; i++){
WTContainer wtc = findContainer(excludedContextNameForPublication[i]);
if (wtc == null) getjobsprops.PrintOut("WTContainer excluded " + excludedContextNameForPublication[i] + " not found or not used");
else {
getjobsprops.PrintOut("found container: " + wtc.getIdentity()); //wt.pdmlink.PDMLinkProduct:291527
qs.appendAnd();
// idA3containerReference ObjectReference.KEY
qs.appendWhere(new SearchCondition(EPMDocument.class, WTContained.CONTAINER_REFERENCE + ".key.id" , SearchCondition.NOT_EQUAL, PersistenceHelper.getObjectIdentifier(wtc).getId()));
}
}
}
-----------------------------------------------8<------------------------------------------------
i.e. Change this:
qs.appendWhere(new SearchCondition(EPMDocument.class, WTContained.CONTAINER_REFERENCE + ".key.id" , SearchCondition.NOT_EQUAL, PersistenceHelper.getObjectIdentifier(wtc).getId()));
to be this:
qs.appendWhere(new SearchCondition(EPMDocument.class, WTContained.CONTAINER_REFERENCE + ".key.id" , SearchCondition.EQUAL, PersistenceHelper.getObjectIdentifier(wtc).getId()));
Oct 09, 2015
08:50 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 09, 2015
08:50 AM
Thanks Gary. These are good answers. Appreciate it.
Oct 12, 2015
06:03 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 12, 2015
06:03 PM
Gary Jackson, I have several questions. For my initial go-around I'm only trying the command line version for CSV publishing.
- I ran the makeCommonUtils.bat and that went fine. I then attempted to run makePublishUtil.bat but that prompted me for Oracle DB information. We are using MS SQL server. Should I point these prompts to the MS SQL equivalents or will they only work with Oracle?
- If I only want to try CSV publishing, is it sufficient to just run makeCommonUtils.bat and makePublishUtilreadCSV.bat and do nothing else (the stuff listed above for additional schedulers, extra properties, and other make files)?
- The PublishUtilreadCSV.bat appears to strip off everything but the OR from CSV file. If that's the case, then is there really any reason to include anything other than just the OR in the CSV file? Do I really need the other columns: OR||DOCNAME||DOCNUMBER
- What exactly is the || character? Normally CSV files are comma separated. I'm not sure if this is supposed to be a TAB or two "pipe" characters.
Thanks!
Oct 12, 2015
07:20 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 12, 2015
07:20 PM
Answering some of my own questions...
Apparently the steps I listed in question #2 were sufficient. Those are the only things I did and the PublishUtilreadCSV.bat is working just fine. Also, I only included the ORs in the text file, so apparently that answers question #3 as well.
One thing you might want to ask the developer. This script appears to delete the existing representation first, then submits the job for publishing. On the other hand, if you resubmit a job from the WVS Job Monitor, it does not delete (or replace) the existing representation unless it is successfully republished. Is there a way to have this script behave that way so that if there's some problem with publishing the existing representations aren't lost? Probably not a big deal, just curious.
991 jobs were just submitted flawlessly.

Thanks again for this!!!
Oct 12, 2015
08:49 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 12, 2015
08:49 PM
Just did my second run on production. The script processed 4,225 items in 44 minutes, so 1.6 objects per second or 96 objects per minute.

In some ways this seems a little slow, but I guess it's not a big deal since I can only publish around 20 objects per minute anyway. 
Loving this!
Oct 14, 2015
12:45 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 14, 2015
12:45 PM
Hi Tom,
Sorry for the delayed reply, I was OOTO yesterday and have only just caught up this afternoon.
Glad to hear that this is helping!
Also glad to hear you've answered your questions #2 & #3! I assume you also have implicitly answered #1, given it's working? Regarding #4, the "||" are just the chosen CSV delimiter (does not have to be a comma and double-pipe is more likely unique.
Gary
Oct 14, 2015
12:51 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 14, 2015
12:51 PM
Tom Uminn wrote:
One thing you might want to ask the developer. This script appears to delete the existing representation first, then submits the job for publishing. On the other hand, if you resubmit a job from the WVS Job Monitor, it does not delete (or replace) the existing representation unless it is successfully republished. Is there a way to have this script behave that way so that if there's some problem with publishing the existing representations aren't lost? Probably not a big deal, just curious.
This is how it's currently designed but refer to the from the TS developer comments paraphrased in my answer to Bill above: 09-Oct-2015 04:12.
Oct 16, 2015
03:20 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 16, 2015
03:20 PM
Still looking for an answer to question #1. Thanks.
I ran the makeCommonUtils.bat and that went fine. I then attempted to run makePublishUtil.bat but that prompted me for Oracle DB information. We are using MS SQL server. Should I point these prompts to the MS SQL equivalents or will they only work with Oracle?.
Oct 19, 2015
04:32 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 19, 2015
04:32 AM
Tom Uminn wrote:
Still looing for an answer to question #1. Thanks.
I ran the makeCommonUtils.bat and that went fine. I then attempted to run makePublishUtil.bat but that prompted me for Oracle DB information. We are using MS SQL server. Should I point these prompts to the MS SQL equivalents or will they only work with Oracle?.
The query script in the source in PublishUtil.java & PublishUtilNoRep.java works for Oracle only, you will need to convert this to MSSQL before using the command-line utilities for an SQL Server configuration.
I'll add a note to the article to this effect.
Oct 19, 2015
08:07 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 19, 2015
08:07 AM
Okay, thanks. Maybe just make sure the note doesn't include that restriction for the PublishUtilreadCSV. That one is working fine with MS SQL.
Oct 19, 2015
11:06 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Oct 19, 2015
11:06 AM
The note is against the command-line tool only.
Gary
