
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Please log in to access translation
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - You can Bookmark boards, posts or articles that you'd like to access again easily! X
- Community
- PLM
- Windchill Discussions
- Re: Resolving Cad Agent Timeout Issues - Resurrect...
Translate the entire conversation x
Please log in to access translation
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Resolving Cad Agent Timeout Issues
Jul 10, 2013
12:48 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 10, 2013
12:48 PM
Resolving Cad Agent Timeout Issues
I am sure we've all seen this from time to time:
Jul 10, 2013 11:33:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:34:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:35:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:36:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:37:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:38:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:39:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:40:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Tech support notes to adjust time out in wvs.properties
publish.cadtimeout.assembly=7200
publish.cadtimeout.component=600
publish.cadtimeout.drawing=7200
Been there, done that. So, with all your publisher queues displaying this scrolling message, is there any hope to fix? I tried deleting the executing jobs and just go to the next one. Those too, end up in this loop. I am looking for something to do without having to restart the system.
Antonio Villanueva - Sr. Software Engineer - ISR Systems
UTC AEROSPACE SYSTEMS
100 Wooster Heights Road, Danbury, CT 06804
Tel: +1 203 797 5682
antonio.villanueva@utas.utc.com<">mailto:antonio.villanueva@utas.utc.com> www.utcaerospacesystems.com
CONFIDENTIALITY WARNING: This message may contain proprietary and/or privileged information of UTC Aerospace Systems and its affiliated companies. If you are not the intended recipient please 1) do not disclose, copy, distribute or use this message or its contents, 2) advise the sender by return e-mail, and 3) delete all copies (including all attachments) from your computer. Your cooperation is greatly appreciated.
Jul 10, 2013 11:33:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:34:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:35:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:36:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:37:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:38:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:39:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Jul 10, 2013 11:40:59 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 60 seconds
Tech support notes to adjust time out in wvs.properties
publish.cadtimeout.assembly=7200
publish.cadtimeout.component=600
publish.cadtimeout.drawing=7200
Been there, done that. So, with all your publisher queues displaying this scrolling message, is there any hope to fix? I tried deleting the executing jobs and just go to the next one. Those too, end up in this loop. I am looking for something to do without having to restart the system.
Antonio Villanueva - Sr. Software Engineer - ISR Systems
UTC AEROSPACE SYSTEMS
100 Wooster Heights Road, Danbury, CT 06804
Tel: +1 203 797 5682
antonio.villanueva@utas.utc.com<">mailto:antonio.villanueva@utas.utc.com> www.utcaerospacesystems.com
CONFIDENTIALITY WARNING: This message may contain proprietary and/or privileged information of UTC Aerospace Systems and its affiliated companies. If you are not the intended recipient please 1) do not disclose, copy, distribute or use this message or its contents, 2) advise the sender by return e-mail, and 3) delete all copies (including all attachments) from your computer. Your cooperation is greatly appreciated.
Labels:
- Labels:
-
Other
16 REPLIES 16
Jul 10, 2013
01:05 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 10, 2013
01:05 PM
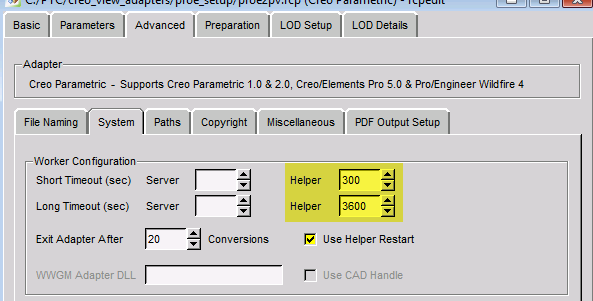
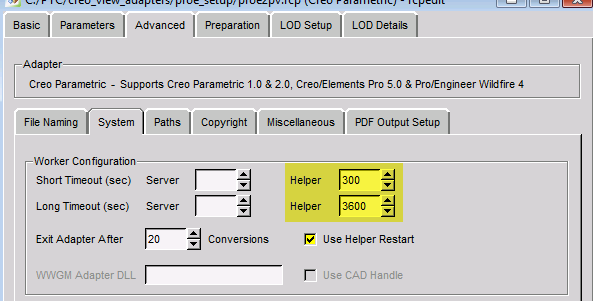
There are also timeout settings in the recipe file as well. I think that could be part of the issue. Try to increase these beyond 60 seconds.
[cid:image001.png@01CE7D6E.273C9780]
Steve D.
[cid:image001.png@01CE7D6E.273C9780]
Steve D.
Jul 10, 2013
01:19 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 10, 2013
01:19 PM
Antonio,
Is there any Firewall enabled on the CADWorker machine? Is the user local admin who is starting the GSWorker Daemon in the services? Shutdown GS Worker Daemon from services and start workerdaemon.exe manually and see if there are any pop-ups.
Thanks,
Kiran Lakshminarayanan
Is there any Firewall enabled on the CADWorker machine? Is the user local admin who is starting the GSWorker Daemon in the services? Shutdown GS Worker Daemon from services and start workerdaemon.exe manually and see if there are any pop-ups.
Thanks,
Kiran Lakshminarayanan
Jul 10, 2013
01:21 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 10, 2013
01:34 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 10, 2013
01:34 PM
These are good suggestions from Kiran.
The other suggestion I would make is to bring up the model in question in Proe on that machine and see if it takes longer to pull up than your timeout or if it has any prompts that require human intervention. In the latter case you would need to fix the model before it can be published.
--Bob
The other suggestion I would make is to bring up the model in question in Proe on that machine and see if it takes longer to pull up than your timeout or if it has any prompts that require human intervention. In the latter case you would need to fix the model before it can be published.
--Bob
Jul 10, 2013
01:46 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 10, 2013
01:46 PM
Does this happen for all jobs, or just some jobs? I know we had an issue with timeouts for Drawings while trying to create the thumbnail. This issue happened/was noticed a few weeks after we upgraded the Adapters to support Creo 1 from Wildfire 5.0. Is there any additional error messages in the worker/helper logs that may be of use? The timeout issue can result in the worker already failing and not communicating back. That's what we found in this case.
You may want to look at these two articles.
You may want to look at these two articles.
Jul 11, 2013
09:39 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 11, 2013
09:39 AM
Hi Antonio,
We had a similar experience but our problem was large assemblies were taking longer than the timeout set in the recipe file. We didn't want to set the timeout too high because it caused the jobs behind it wait for too long. The solution was to split out the long running jobs (large assemblies) to their own queue set and have a dedicated worker process all of those jobs. Then, the timeout in the dedicated worker's recipe file could be as high as it needed to be without blocking smaller jobs.
We also put the publishing queues on their own background method server. That way, when something happened (all got stuck in the executing state) we could just kill that bgms and not hurt anything happening on the ootb bgms.
Let me know if you want more information on either solution.
~Jamie
Jul 11, 2013
10:33 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 11, 2013
10:33 AM
I just started having a timeout issue that started yesterday, but is only on one assembly. I happened to check the trail file on the worker and it gives me this wonderful error:
! Message Dialog: Warning
!mem_use INCREASE Blocks 2338088, AppSize 259071815, SysSize 294674976
! : Fatal error encountered. A traceback has been written to
! : D:\ptc\creoelements_viewadapters\proe_setup\traceback.log
! : Please send it to Technical Support.
Any ideas? It pulls up quickly on the users machine. This doesn't seem to be an actual timeout, so hopefully someone else has had this issue.
Brian Toussaint
CAD Administrator
Hoshizaki America, Inc.
"A Superior Degree Of Reliability"
618 Hwy. 74 S., Peachtree City, GA 30269
Phone: (770) 487-2331 ext. 1216
Fax: (770) 487-3359
www.hoshizaki.com
! Message Dialog: Warning
!mem_use INCREASE Blocks 2338088, AppSize 259071815, SysSize 294674976
! : Fatal error encountered. A traceback has been written to
! : D:\ptc\creoelements_viewadapters\proe_setup\traceback.log
! : Please send it to Technical Support.
Any ideas? It pulls up quickly on the users machine. This doesn't seem to be an actual timeout, so hopefully someone else has had this issue.
Brian Toussaint
CAD Administrator
Hoshizaki America, Inc.
"A Superior Degree Of Reliability"
618 Hwy. 74 S., Peachtree City, GA 30269
Phone: (770) 487-2331 ext. 1216
Fax: (770) 487-3359
www.hoshizaki.com
Jul 11, 2013
11:25 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 11, 2013
11:25 AM
Thanks to those who are responding. This has been a great thread. My biggest frustration is that its not anything simple. The system (I believe) is configured fine. Timeout values are ok. Its not related to a bad assembly. We ended up bouncing the system and it all came back to life. The jobs that were hanging not processed with no issues, complete. During the issue, we also got calls that workflow tasks had stopped moving and there was a high number of active contexts on the background methodserver. It did not show high CPU or GC %. My technical term for this was its "out to lunch" and it was in fact lunch time.
It explained why the CadAgent was timing out. What I need a deeper understanding is where is the CadAgent running. I think some people on the threads were confusing the publisher, queues, agents, workers and helpers. I do not believe this was an issue on the Cad Worker machine (Daemon, helpers or workers). They were not getting any jobs to them. I could start and stop them with no issues.
My point of the thread was to see if there was a way, short of reboot, to return the background MS to normal operation. To unstick what was stuck. If there was some thread or process within the system, it would sure be nice to reach in an diagnose it without bringing the whole system down. That, in the end, is what we were forced to do.
It explained why the CadAgent was timing out. What I need a deeper understanding is where is the CadAgent running. I think some people on the threads were confusing the publisher, queues, agents, workers and helpers. I do not believe this was an issue on the Cad Worker machine (Daemon, helpers or workers). They were not getting any jobs to them. I could start and stop them with no issues.
My point of the thread was to see if there was a way, short of reboot, to return the background MS to normal operation. To unstick what was stuck. If there was some thread or process within the system, it would sure be nice to reach in an diagnose it without bringing the whole system down. That, in the end, is what we were forced to do.
Jul 11, 2013
01:14 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jul 11, 2013
01:14 PM
We've had times where I've caused issues with the publishing queue and we found that we could kill the background m.s. process and servermanager will fire up a new one and operations will return to normal. This allows us not to have to bring down the whole application. This is probably not a best practice but it has worked for us when restarting the application would not be ideal.
Steve D.
Steve D.
Sep 13, 2018
08:13 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Sep 13, 2018
08:13 AM
After all these years, this issue confounds me. Tech Support has been useless (you have) on this issue. No one has yet gotten to root cause. What frustrating is there are so many links in the chain that its tough to diagnose. The only thing I do know is that the suggestion of restarting the Background MS was the only thing that remedied the issue but does not solve it. Users are typically unaware of the restart.
I now run multiple PDMLink 10.2 and 10.1 installations and all have the issue to some degree. I cannot queue up a scheduled republish job since it will never complete without baby sitting the queue. I am ok with it skipping and moving on to next job but it stalling all together needs to be solved.
Here is what I know:
- Issue seems to be in the Background MS since restarting it resolved it. Any changes on the CAD worker have no effect.
- It does not appear to be data dependent but I have not 100% ruled that out.
- Typically it starts after a job has failed some some reason but some thread does not end, blocking the entire queue. Typically it would fail at the step of "generating thumbnail" but I have seen other jobs fail there an not hold up queue..
- Killing the executing queue jobs does not resolve the issue. No trick appears to work.
- Configuration - 3MS-1BGMS-3 queues-3 Creo workers on single workstation (using virtual host callouts). Linux to Windows over SFTP transfer.
At this point, since I am seeing it all over, I am open to all options. I have thought about splitting off publishing to its own BGMS, creating a thumbnail worker exclusively. I have played with timeout settings but issue seems to remain. Anyone else still seeing this or has solved it?
- No alert I know of can tell me when its occurring other than the users reporting jobs are not processing.
Sep 14, 2018
12:27 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Sep 14, 2018
12:27 PM
- Configuration - 3MS-1BGMS-3 queues-3 Creo workers on single workstation (using virtual host callouts). Linux to Windows over SFTP transfer.
On your worker, have you updated your local hosts file with your 3 aliases in windows\system32\drivers\etc\hosts? Sounds like you have it on the server side in /etc/hosts, but the worker needs to know about these too.
Did you manually add the correct alias to proeworker.bat as -DA <alias>? Keep in mind that the preo2pv gui tool overwrites this.
For troubleshooting hung creo processes, Resource Monitor is a great tool because you can filter on your different worker paths. Next time try identifying the hung job, killing the xtop.exe process, and see if it's able to continue.
Sep 14, 2018
12:36 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Sep 14, 2018
12:36 PM
Yes, hosts and setup is all correct. As I stated, it publishes correctly 99% of the time. This is a toughie since its random and extremely time consuming to debug. I can't also play in production like when tech support suggest to make prop file changes and see what happens. Can't exactly just reboot in middle of day to try that.
Sep 24, 2018
03:56 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Sep 24, 2018
03:56 PM
Replying to myself - Had issue occur on two systems in the same day. Fixed both by restarted BGMS. Both failed in exactly the same place:
Sep 23, 2018 11:34:58 PM: Getting Mass Properties
Sep 23, 2018 11:34:58 PM: Converting Author States
Sep 23, 2018 11:34:58 PM: Generating Output
Sep 23, 2018 11:34:58 PM: Generating thumbnail
Sep 24, 2018 12:34:58 AM:Timeout exceeded waiting for a reply from the CadAgent - Time out 3,600 seconds
Sep 24, 2018 12:34:58 AM:Asm Processing Returned: $ERROR$ Timeout exceeded waiting for a reply from the CadAgent - Time out 3,600 seconds
Sep 24, 2018 12:34:58 AM:Attempting to delete temporary workspace publish7290478894723542735tmp
Open to anything here. Should I direct the workers not to create thumbnails and just create a separate thumbnail worker? Or would that just increase processing time?
Sep 25, 2018
04:40 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Sep 25, 2018
04:40 AM
This has been a long term issue with me as well. Over two companies and two different CAD platforms and three different versions of Windchill. One would think such a fundamental issue could be solved, restarting is ok, and gets you going, - but what is the problem to begin with? I'm commenting primarily to follow this thread in the hopes of gleaning some insight. 🙂
James Hall
PLM Administrator/Analyst
Swisslog Healthcare (North America)
Windchill 11.0 M030 CPS09
WGM 11.0 M030
Inventor Pro 2017
Oct 02, 2018
05:48 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Oct 02, 2018
05:48 AM
I just had an admin republish a context with 3000 jobs. It may go a few hours before stalling. Given the daily load, it really is frustrating that current requests are getting hung up. I "think" this might be another work around. If I see a job that is spinning away at the state of publishing thumbnail (whether it has done this already or not), usually, it should not take a long time. If it does, you can go to Queue manager and delete the executing job. System might not stall but again, it takes periodic monitoring.
Mar 19, 2021
02:36 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Mar 19, 2021
02:36 PM
Speaking about resurrecting...
I came across your discussion today when one of our customers had this exact same issue with their CAD worker. The solution in their case was this article: https://www.ptc.com/en/support/article/CS332276The issue at their end was caused by VMWare Tool. I don't know if this is of any help to your case, nor if you still have an issue with this, but if you do maybe it can be of some help.





{kind=link}
{kind=link}
{kind=link}