
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - Want the oppurtunity to discuss enhancements to PTC products? Join a working group! X
- Community
- Arbortext
- Arbortext Tips
- New Features Coming in Styler 6.0 M020 - Accessibi...
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Notify Moderator
New Features Coming in Styler 6.0 M020 - Accessibility
No ratings
This is the third and final posting from me on the new functionality coming in the M020 release of Styler 6.0. This time I look at some work we've been doing to improve the accessibility of HTML and PDF output from Styler.
Anyone familiar with document requirements for governmental departments in the US will probably have come across the term Section 508. In the US and elsewhere around the world you might also have come across the Web Content Accessibility Guidelines published by the W3C. These requirements are focussed on making published content accessible to readers who have trouble seeing, moving or otherwise accessing information delivered electronically. A number of the requirements for these standards are to do with how the information is displayed - not having moving backgrounds or using absolute sizes for text on a web page - but some are to do with how the information being delivered is encoded. And this is where Styler can make a difference.
A large part of what's needed is to improve the level of information available about the content, whether publishing HTML or PDF, so that 'assistive technologies' such as screen readers can gather meaning or alternative information about the content. For example, a graphic isn't very useful if you're blind so providing alternative text which describes the graphic will help a blind reader to appreciate the document as much as someone who can see.
HTML already has a tagging structure which can give meaning and information. Semantic HTML tags such as <H1> and <LI> can tell assistive technologies that they are reading a heading or a list item. Alternative text for items can be provided through the 'alt' attribute value on many HTML tags.
PDF typically doesn't have the same level of structure as HTML, but PDFs can be 'tagged'. Tagged PDFs have markers around content blocks which, as with HTML, provide some meaning to assistive technologies. The default PDF tagging structures are very similar to HTML tags but they can include custom names. Alternative text for graphics is also catered for, as is the ability to spell out abbreviations and to provide alternative text for whole content blocks. Tagged PDFs also provide the PDF with some order so that the assistive technology knows which blocks of content follow which.
So, what are we doing in M020 to make this stuff easier? Nice things!
Let's look at stylesheet properties first.
- In the HTML tab, there is a new option to 'Generate semantic HTML/XHTML'.
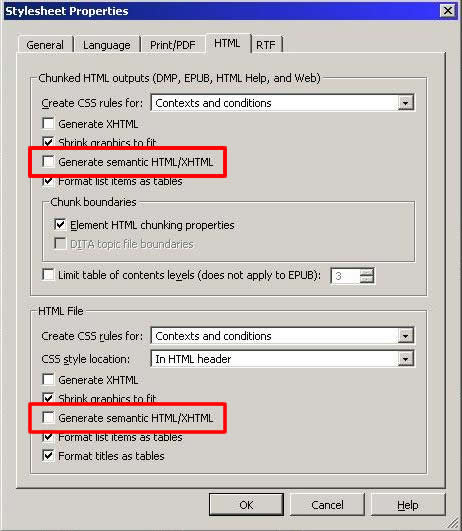
This option will tell Styler to generate <p> and <h1> type HTML tags rather than the <div> and <span> tags it was generating before. As I mention above, this gives the assistive technologies a better idea of the meaning of the content. - In the PDF tab, if you have APP selected as your output engine, there is a new 'Generate Tagged PDF' option.

This option will tell APP to generate a tagged PDF.
With both HTML and PDF tagging, a set of default tags will be applied based on the style applied to the element in Styler. But what if you want to change it? Styler has a new 'Tags' tab which allows you to set the HTML and PDF tag you wish to generate for each element, context or even condition.
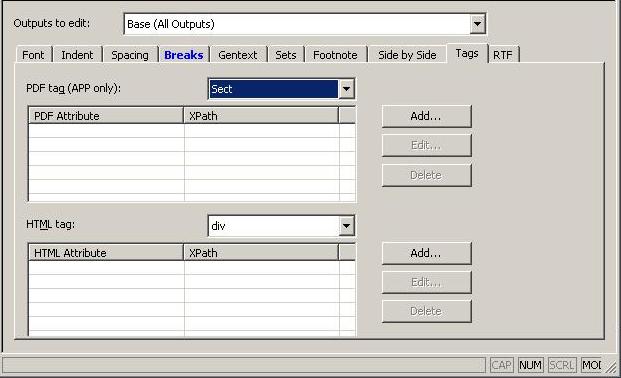
The Tags tab allows you to set the PDF and HTML tags. The list of tags available is derived from what makes sense for the styled element in Styler (so you can't tell a list item to be the document root). Also on this tab is the ability to set attribute values on the tags being generated.
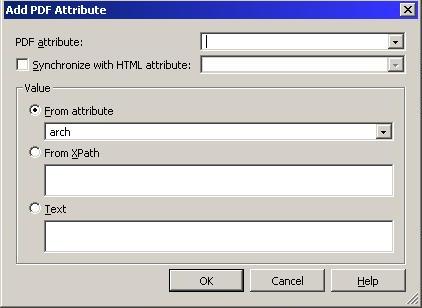
This is where you would set the 'Alternate text' for graphical components, for example. Attribute values can be generated from an attribute value in your XML, from an XPath expression or you can key the value in yourself. To save time, the PDF attribute can be told to match that you apply in HTML.
I'm sure you'll agree that will make a big difference to the output generated from Styler. You're now in much greater control of the HTML output and PDF tagging for accessible output is now available. Together with other CSS enhancements made in 6.0 there are some great tools in Styler to make it easier for you to create and style HTML from your XML. So these features are of great benefit for everyone, not just those wanting to create 'accessible' output.
I hope you enjoy using this feature - if you have any feedback, please feel free to get in touch.
As ever, this is forward looking information so subject to change without notice.
Comments
May 22, 2013
06:06 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
May 22, 2013
06:06 AM
I have a question, When tagged PDF is publish, How can I know if the tag is correct?
By the way, it seems tag needs to be defined for element each by each, if there are lots of Element, condition or context in the XML document, it would be a huge work, right?
