
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Please log in to access translation
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Community
- IoT & Connectivity
- IoT & Connectivity Tips
- Troubleshooting example of extremely slow server p...
Please log in to access translation
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Notify Moderator
Troubleshooting example of extremely slow server performance with low CPU consumption
No ratings
Please log in to access translation
In this particular scenario, the server is experiencing a severe performance drop.The first step to check first is the overall state of the server -- CPU consumption, memory, disk I/O. Not seeing anything unusual there, the second step is to check the Thingworx condition through the status tool available with the Tomcat manager.
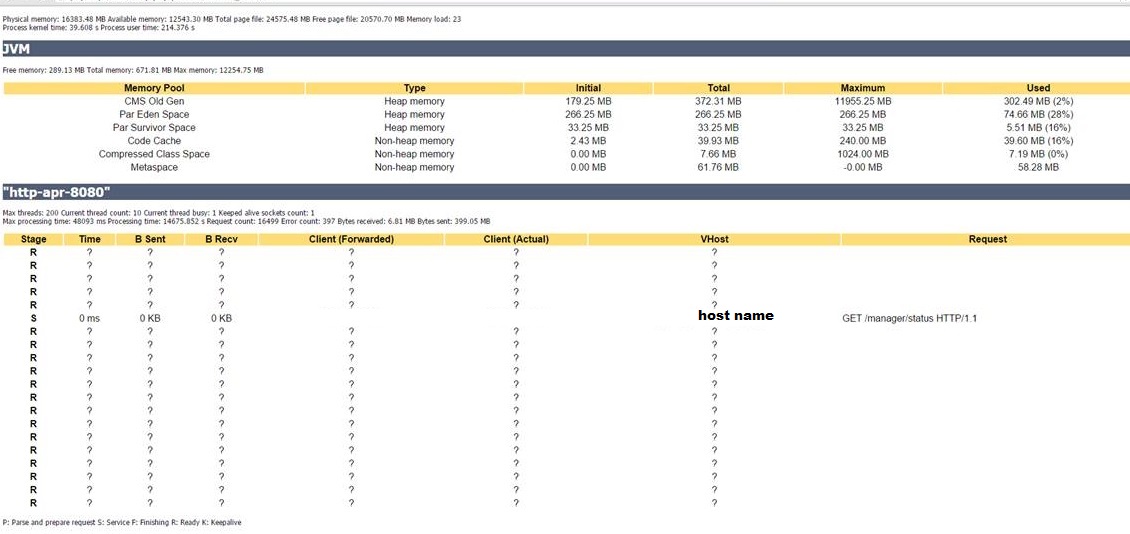
Per the observation:
- Despite 12 GB of memory being allocated, only 1 GB is in use.
- Large number of threads currently running on the server is experiencing long run times (up to 35 minutes)
Checking Tomcat configuration didn't show any errors or potential causes of the problem, thus moving onto the second bullet, the threads need to be analyzed.
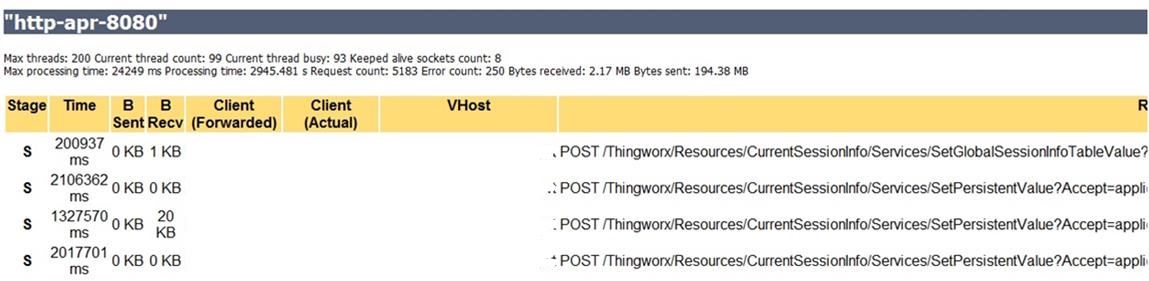
That thread has been running 200,936 milliseconds -- more than 3 minutes for an operation that should take less than a second. Also, it's noted that there were 93 busy threads running concurrently.
Causes:
- Concurrency on writing session variable values to the server.
- The threads are kept alive and blocking the system.
Tracing the issue back to the piece of code in the service recently included in the application, the problem has been solved by adding an IF condition in order to perform Session variable values update only when needed.
In result, the update only happens once a shift.
Conclusion: Using Tomcat to view mashup generated threads helped identify the service involved in the root cause. Modification required to resolve was a small code change to reduce the frequency of the session variable update.
Comments
Jan 30, 2017
03:13 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Jan 30, 2017
03:13 AM
Hi Polina,
Don't you think that was caused for a blocking condition? That's usual the reason of a thread that never ends despite doesn't consumes CPU. If that's the case you may not solved the issue with your IF condition, when you have more users / machines on the platform you may face it again.
An the other thing, if the blocking condition was due a transactional reason, with which Database where you doing the tests?
Carles.
Jan 30, 2017
09:25 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Jan 30, 2017
09:25 AM
Hi Carles,
This is a real case scenario example on how to use the tools available to troubleshoot one of the possible causes for slow performance. Depending on the system and individual aspects of the application, the causes would vary yet the tools and approaches may be used in a similar manner, to narrow down the issue or to eliminate a possible cause. This serves more as a reference to the tools capabilities rather than a guaranteed cause determination. Sometimes it helps to remember of a possibility for the user logic fault, aside from the system's/its resources. In the majority of similar situations, the programmatic/logical cause is easily overlooked.
This particular scenario happened with the Neo db.
