
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Please log in to access translation
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Community
- IoT & Connectivity
- IoT & Connectivity Tips
- Best Practices in Data Preparation for ThingWorx A...
Please log in to access translation
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Notify Moderator
Best Practices in Data Preparation for ThingWorx Analytics
No ratings
Please log in to access translation
Best Practices in Data Preparation for ThingWorx Analytics
Data Preparation is an important phase in the process of Data Analysis when using ThingWorx Analytics. Basically, it is getting your Data from being Raw Data that you might have gathered through your Operational system or from your Data warehouse to the kind of Data ready to be analyzed.
In this Document we will be using “Talend Data Preparation Free Desktop” as a Tool to illustrate some examples of the Data Preparations process. This tool could be downloaded under the following Link:
https://www.talend.com/products/data-preparation
(You could also choose to use another tool)
We would also use the Beanpro Dataset in our Examples and illustrations.
Checking data formats
The analysis starts with a raw data file. The user needs to make sure that the data files can be read.
Raw data files come in many different shapes and sizes. For example, spreadsheet data is formatted differently than web data or Sensors collected data and so forth.
In ThingWorx Analytics the Data Format acceptable are CSV. So the Data retrieved needs to be inputted into that format before it could be uploaded to TWA
Data Example (BeanPro dataset used):

After that is done the user needs to actually look at what each field contains. For example, a field is listed as a character field could actually contains none character data.
Verify data types
Verifying the data types for each feature or field in the Dataset used. All data falls into one of four categories that affect what sort of analytics that could be applied to it:
- Nominal data is essentially just a name or an identifier.
- Ordinal data puts records into order from lowest to highest.
- Interval data represents values where the differences between them are comparable.
- Ratio data is like interval data except that it also allows for a value of 0.
It's important to understand which categories your data falls into before you feed it into ThingWorx Analytics. For example when doing Predictive Analytics TWA would not accept a Nominal Data Field as Goal.
The Goal feature data would have to be of a numerical non nominal type so this needs to be confirmed in an early stage.
Creating a Data Dictionary
A data dictionary is a metadata description of the features included in the Dataset when displayed it consists of a table with 3 columns:
- The first column represents a label: that is, the name of a feature, or a combination of multiple (up to 3) features which are fields in the used Dataset. It points to “fieldname” in the configuration json file.
- The second column is the Datatype value attached to the label. (Integer, String, Datetime…). It points to “dataType” in the configuration json file.
- The third column is a description of the Feature related to the label used in the first column. It points to “description” in the configuration json file.
In the context of TWA this Metadata is represented by a Data configuration “json” file that would be uploaded before even uploading the Dataset itself.
Sample of BeanPro dataset configuration file below:

Verify data accuracy
Once it is confirmed that the data is formatted the way that is acceptable by TWA, the user still need to make sure it's accurate and that it makes sense.
This step requires some knowledge of the subject area that the Dataset is related to.
There isn't really a cut-and-dried approach to verifying data accuracy. The basic idea is to formulate some properties that you think the data should exhibit and test the data to see if those properties hold. Are stock prices always positive? Do all the product codes match the list of valid ones? Essentially, you're trying to figure out whether the data really is what you've been told it is.
Identifying outliers
Outliers are data points that are distant from the rest of the distribution. They are either very large or very small values compared with the rest of the dataset.
Outliers are problematic because they can seriously compromise the Training Models that TWA generates.
A single outlier can have a huge impact on the value of the mean. Because the mean is supposed to represent the center of the data, in a sense, this one outlier renders the mean useless.
When faced with outliers, the most common strategy is to delete them.
Example of the effect of an Outlier in the Feature “AVG Technician Tenure” in BeanPro Dataset:
Dataset with No Outlier:
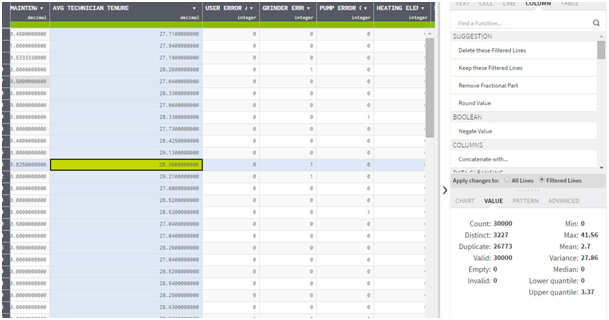
Dataset with Outlier:
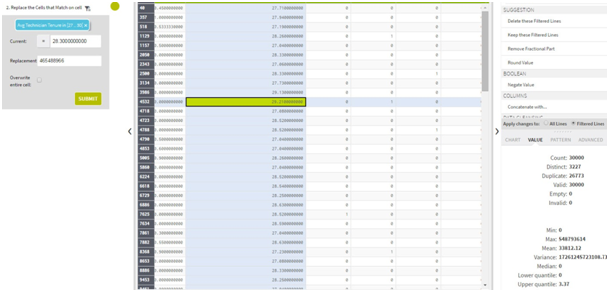
Deal with missing values
Missing values are one of the most common (and annoying) data problems you will encounter.
In TWA dealing with the Null values is done by one of the below methods:
- Dropping records with missing values from your Dataset. The problem with this is that missing values are frequently not just random little data glitches so this would consider as the last option.
- Replacing the NULL values with average values of the responses from the other records of the same field to fill in the missing value
Transforming the Dataset
- Selecting only certain columns to load which would be relevant to records where salary is not present (salary = null).
- Translating coded values: (e.g., if the source system codes male as "1" and female as "2", but the warehouse codes male as "M" and female as "F")
- Deriving a new calculated value: (e.g., sale_amount = qty * unit_price)
- Transposing or pivoting (turning multiple columns into multiple rows or vice versa)
- Splitting a column into multiple columns (e.g., converting a comma-separated list, specified as a string in one column, into individual values in different columns)
Please note that:
- Issue with Talend should be reported to the Talend Team
- Data preparation is outside the scope of PTC Technical Support so please use this article as an advisable Best Practices document
