
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Please log in to access translation
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - Need to share some code when posting a question or reply? Make sure to use the "Insert code sample" menu option. Learn more! X
- Community
- PLM
- Windchill Tips
- Improving search performance with the SubStringInd...
Please log in to access translation
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Notify Moderator
Improving search performance with the SubStringIndexTool in Windchill
No ratings
Please log in to access translation
I’m sure that many of you have come across slow-performing searches in Windchill, especially when using wildcards. It might be snappier if you have Index Search installed, but only when the Keyword: field is used; as soon as you enter something in the Criteria section of Advanced Search, the system falls back to basic database queries.
Under the hood, the bulk of the time and resources spent during wildcard search is in database queries containing something like "..AND NAME LIKE ‘%mypart%’…", i.e. with filters that include leading and/or trailing wildcards.
New functionality was introduced in Windchill 10.2 to deal with this. The basic idea is that, for a given business object type and attribute, a separate table is created in the database that holds indexed columns with substrings of the current values. Windchill can then do exact searches of these substrings without using wildcards, which speeds things up significantly. We’ll go through an example here to illustrate how to use it.
Configuring it
I’ll be adding a substring index for the attribute ‘name’ in the business object class wt.part.WTPartMaster. The actual creation and maintenance of the substring index tables is done with the SubStringIndexTool, but before running it, it needs to be configured.
The tool reads the configuration file <Windchill>/conf/subStringIndex.xml. This file does not exist in OOTB Windchill, so I’ll have to create it manually.
For this example, the content of the file looks like this:
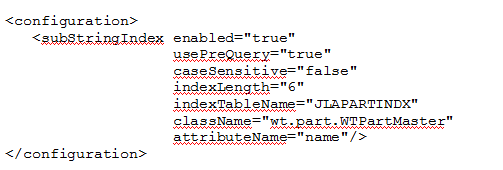
The parameters className and attributeName are set to the class and attribute on which the substring index is created. I want the index table name to be JLAPARTINDX; if this is not specified, it will default to <table>$<attribute>$SSI, which is a bit long for my taste. I don’t want it to be case sensitive (caseSensitive=”false”) and the index length is set to 6 (indexLength=”6”). I’ll cover that later when we look at the results.
I’m also enabling pre-query, which is one of two available approaches for applying the substring index during searches. The one chosen here means that Windchill first queries the substring index table for matching object IDs; these are then used to query the actual business object table. There are more details on this in the JavaDoc of the wt.pds.subStringIndex package.
With the configuration done, we can run the tool to create the substring index.
Running the tool
The substring index is created with the following command:
windchill wt.pds.subStringIndex.SubStringIndexTool create <user> <password>
where <user> and <password> is the Windchill database schema username and password. The result is a new table that looks something like this:
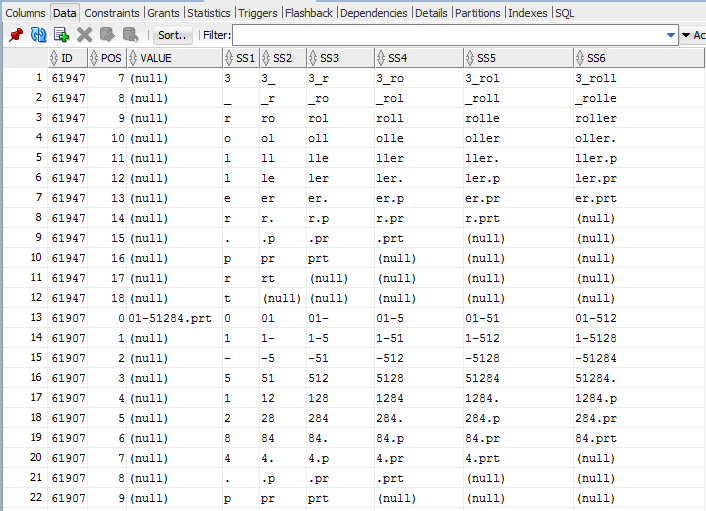
The ID column holds the object ID of the related WTPartMaster; the VALUE column holds the full values of the selected ‘name’ attribute. The SS* columns hold the substrings of the given lengths that have been found in the attribute values. This is where the ‘indexLength’ parameter comes in; it was set to 6, so it will generate six SS* columns. SS1 holds all substrings of length 1, SS2 holds the ones with length 2, and so on.
For example, one of the attribute values is '01-51284.prt'. The substrings for this value start in row 13 above: as the POS value increases, you see the various length substrings for that value in the different SS* columns.
So how does it work? Say a user does a search for *5128*. The substring between the wildcards is four characters long, so a fast, indexed search is done in the SS4 column for the exact value 5128. The query returns the ID column values, which are then used to find the matching entries in the original WTDOCUMENTMASTER table.
Maintaining it
A separate table is being used for the substring indexes, which means that a mechanism is needed to keep it in sync with the original business object table. There are three options:
- Event-driven – sync is triggered insert, update and/or remove events in Windchill
- Scheduled – sync takes place at scheduled, regular intervals, triggered from a background queue.
- Manual – sync is done manually with the SubStringIndexTool
This is configured in the subStringIndex.xml file mentioned earlier. Details on these and how to configure them can be found here.
Going forward
If this looks interesting and you wish to implement substring indexes, you’ll find further information in the Windchill Help Center. The purpose of this blog entry was to raise awareness of its existence, as we have seen very few queries on it in Tech Support.
Thank you for your time; as always, comments and feedback are greatly appreciated.
Comments
Aug 10, 2015
07:29 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Aug 10, 2015
07:29 PM
Awesome! Didn't know this. Thanks a lot for sharing!
I'll try this a.s.a.p.
Aug 11, 2015
03:32 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Aug 11, 2015
03:32 AM
Hi Johannes,
Thank you for your kind words, glad you liked it!
Aug 11, 2015
09:39 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Aug 11, 2015
09:39 PM
Sounds interesting. However, will it be useful if the system is configured to use solr indexing on dedicated server? Also, looks like we will end up creating tables to maintain indexes. Also, needs listener to keep it synced up, it will be interesting to get feedback from large scale customers.
Aug 12, 2015
04:15 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Aug 12, 2015
04:15 AM
Hi Chetan,
Thank you for your comment!
If you have Solr installed, the benefit of substring indexes would depend on the search habits of the end users. If all they ever use is the Keyword: field, then Solr index searches will always be performed and there would be little need for substring indexes. However, as soon as a user adds something in the Criteria: section in Advanced Search, Windchill falls back to database table searches. The end user will then experience performance inconsistencies: an initial search with only Keyword: is fast, but when entering additional info in the Criteria: section, the search is slower. This is where the substring indexes can really make a difference.
Indeed, using substring indexes have overheads such as the required additional tables in the database schema and the processing required to keep them in sync. I haven't seen any metrics on how much of an overhead this is on systems with large data sets, so I agree with you: if any reader applies this on larger data sets, it would be great if you could share info such as search time improvements, size of the substring index tables vs. the original tables, sync overhead, etc.
Aug 18, 2015
10:37 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Aug 18, 2015
10:37 AM
Hello
interesting post. Thanks a lot. We have struggled for about 4years with speed of search..... not sure if this post would have helped as it was under 9.1. Since then we solved the issue by playing on many areas
move to 10.1 (the speed of the search was not the main reason for the upgrade)
new hardware and dedicated server for the database
fine tune the oracle database
set by default that not All object type to be searched for (this one was a killer !!!)
I keep this post handy for my next implementation 
Johan, you are asking if any of your customers with large data sets to try and feedback. I am more in the view that PTC should have enough capacity and resources to test this is inform us the customers, rather than being used as guinea pig ?
Surely it should not be complicated to create randomly a large data set. I have done this for CAD data to test the model of the parameter structures with the users. In a few hours we created over 10 000 EPMDocument with CAD files having parameters so we could test our new parameter structures.
Best regards
Aug 21, 2015
09:56 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Aug 21, 2015
09:56 AM
Hello Chris,
Thank you for your comments!
With regard to the customer feedback aspect: the purpose is not for customers to do the testing for us, we certainly do our own testing and have benchmark suites for various aspects of Windchill functionality (in all fairness, I haven't checked if there is a benchmark suite for substring indexes in particular).
However, these still remain approximations of actual production data, so it's useful to complement that with performance metrics from actual production systems whenever possible. It gets particularly interesting if the performance metrics deviate in any way from a standard benchmark, it gives us an opportunity to learn things such as:
- Are there particular combinations / structures of business data that cause problems? This may help us to improve the product itself as well as benchmarks and QA testing to cover these areas in the future.
- Are there additional application or database configuration settings that further improve or impede the performance of e.g. substring indexes? We can then document these in the HelpCenter or in articles.
The theory behind the substring indexes is pretty straightforward and should work well (read: improve search performance) in most cases, but it's good to be able to reinforce that with metrics from the real world.
Aug 21, 2015
10:47 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Aug 21, 2015
10:47 AM
Hello
thank you for your details comment. I appreciate the professionalism of PTC. I have worked with PTC product since 2007 and must say I am very pleased with the products, the vision of PTC for future new releases, please keep ahead of your competitors .
Feedback from end users is always important. Thanks
Have a good weekend.
Sep 08, 2015
03:49 PM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Sep 08, 2015
03:49 PM
Hello,
Thanks for you article. we really like this concept. I have following query for this. Can you please advise it.
- I hope this substringindex tool store index in DB. Does they impact any performance Issues in DB Side?
- If you have benchmark of storage size in DB, can you share storage size of 1000 parts contain 10 GB of space. we regularly doing DB backup for weekly & Yearly.so we need to know how much storage space requires.
Sep 09, 2015
09:48 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Sep 09, 2015
09:48 AM
Hello,
Thank you for your comment!
With regard to your questions:
1. Yes indeed, the substring indexes are stored in separate tables in the database schema. They are used for exact queries against indexed columns which should be fast and efficient, so the impact should be minimal from a performance point of view.
2. That's an interesting question. First of all, you get one table for each selected type/attribute pair; for example, if you create substring indexes for the NAME and NUMBER attributes of parts, you get two substring index tables, one for each attribute. The size of these tables depends very much on the length of the row data of the chosen column as well as the chosen length of substring.
For example, in my case in the posting, I created a substring index on the 'name' attribute with a chosen substring length of 6. You can see the resulting substring table in the screen shot above; you get one column for each substring length (1 to 6) and effectively one row for each character. If we look at the name value of '01-51284.prt' in the table above, this is 12 characters long, so we get 12 rows with substrings of length 1 to 6 for each of the 12 positions, if that makes sense. This means that we can at least estimate the size of the SS* columns in terms of how many characters are stored.
In the example, the sum of characters in the SS* rows is 6+5+4+3+2+1 = 21. This can be viewed as a triangular number, so can be calculated with the formula (len * (len + 1) / 2) = 21. We get some empty row values towards the tail end of the substring as you can see in the screen shot, but the space is still allocated as the column type is a fixed number of characters(the Oracle column type is CHAR(n) ).
I can then count the total number of characters that will be stored in the SS* columns with the following SQL query:
select sum(21 * length(name)) as tot_size from wtpartmaster;
This yields 173316 characters in my case. I use multibyte character sets in my database which uses three bytes per character, so the size in bytes is then 173316 * 3 = 519984, approximately 500k. There is some additional overhead from the VALUE column, which is essentially the sum of characters in the original table and column, around 8000 in my case. The bulk of the space is taken up by the SS* columns though, so the sum of those should give you some idea.
So, the main deciding factors in how big the substring index table gets are:
- The length of the strings in the original table column
- The chosen substring index length
The latter has a big impact; for example, in my case, the projected character count for the SS* columns are 86658, 173316 and 291486 for substring index length 4, 6 and 8, respectively.
I hope this helps; the formulas above are a bit crude and could do with some refinement to improve the accuracy of the estimation, but it should give you some idea.
Best regards,
Johan
Sep 09, 2015
10:03 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Sep 09, 2015
10:03 AM
Hi Johan,
I would appreciate your answer. It really helps me lot.
Apr 06, 2020
09:41 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Apr 06, 2020
09:41 AM
Hi Johan,
Is there any change with this topic now we are at WC 11.n or 12.n in 2020? It would be good to get an update on this please. (We are actually staying with WC 11.n in the foreseeable future.)
Thanks
Rick
Jul 08, 2020
10:59 AM
- Mark as Read
- Mark as New
- Bookmark
- Permalink
- Notify Moderator
Please log in to access translation
Jul 08, 2020
10:59 AM
@JohanLang Is there an update per @rleir post?
