
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Please log in to access translation
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Community
- PLM
- Windchill Discussions
- Re: Poor Windchill Performance after upgrade to 10...
Translate the entire conversation x
Please log in to access translation
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Poor Windchill Performance after upgrade to 10.2 M030 CPS02
May 27, 2015
09:23 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
May 27, 2015
09:23 AM
Poor Windchill Performance after upgrade to 10.2 M030 CPS02
This past weekend we updated our Windchill System from 10.2 M020 to 10.2 M030 CPS02. Since then we have been experiencing significantly slow performance with multiple Method Servers becoming deadlocked and the DB maxing out.
Is anyone here running 10.2 M030 CPS02 and have/are you experiencing similar issues?
Labels:
- Labels:
-
Other
15 REPLIES 15
May 27, 2015
10:31 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
May 27, 2015
10:31 PM
We are yet to go live with M030 but have experienced several issues as a result of that specific Maintenance release, as a result we are waiting for CPS04 and will revisit the update to M030 at that point.
What Windchill OS and DB are you using?
I am interested to hear if you uncover the root cause of the issues and any resolutions.
May 28, 2015
12:32 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
May 28, 2015
12:32 PM
Our OS is Windows Server 2008 R2 and our DB is SQL Server 2008 R2.
Its currently looking like the upgrade script removed some indexes from the DB that Windchill was using to assist with performance issues. We recreated the missing Indexes in the DB and that has significantly improved our performance. We are still have some issues with deadlocked methodservers but PTC is working on getting us a hotfix for it. Being told this hot fix is coming out with CPS04
Jun 05, 2015
07:46 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 05, 2015
07:46 PM
We recently published a bulletin regarding deadlocked Method Servers. It would be useful to follow the progress of it. Information is located here:
http://support.ptc.com/appserver/wcms/standards/freefull.jsp?&im_dbkey=166606&im_language=en
Jun 11, 2015
06:37 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 11, 2015
06:37 AM
Hi Lori,
We were the ones that found the issue and are running the Hotfix patch provided to us prior to this patch release.
Jun 11, 2015
06:40 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 11, 2015
06:40 AM
Hi Stephen,
the patch PTC provided to you does fix the issue?
Marco
Jun 15, 2015
06:14 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 15, 2015
06:14 AM
It has stopped the deadlocks from occurring, although the deadlocks were being caused by several long running SQL queries that flat lined our DB for a little while.
May 28, 2015
04:55 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
May 28, 2015
04:55 AM
We have deployed 10.2 M030 CPS01 on a development system. This seems to perform reasonable but there is not much load on the system. We are using Redhat Linux and an Oracle 11g Database.
We will need functionality fixed in CPS04 so I am interested on the reason to this performance problems. So I am interested in the root cause, too. The release notes for CPS03 still gave no clue about fixed performance problems.
Deadlocked method servers are likely the result of database locks and/or insufficient db connections. Maybe you get a clue by looking at the database.
May 31, 2015
07:43 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
May 31, 2015
07:43 PM
Do you see anything in the activity monitor? We experienced a deadlock scenario with severe performance issue. This was due to a deadlocked caused by publisher queue.
We used some of the reports from SQL Server to trace back to the transaction.
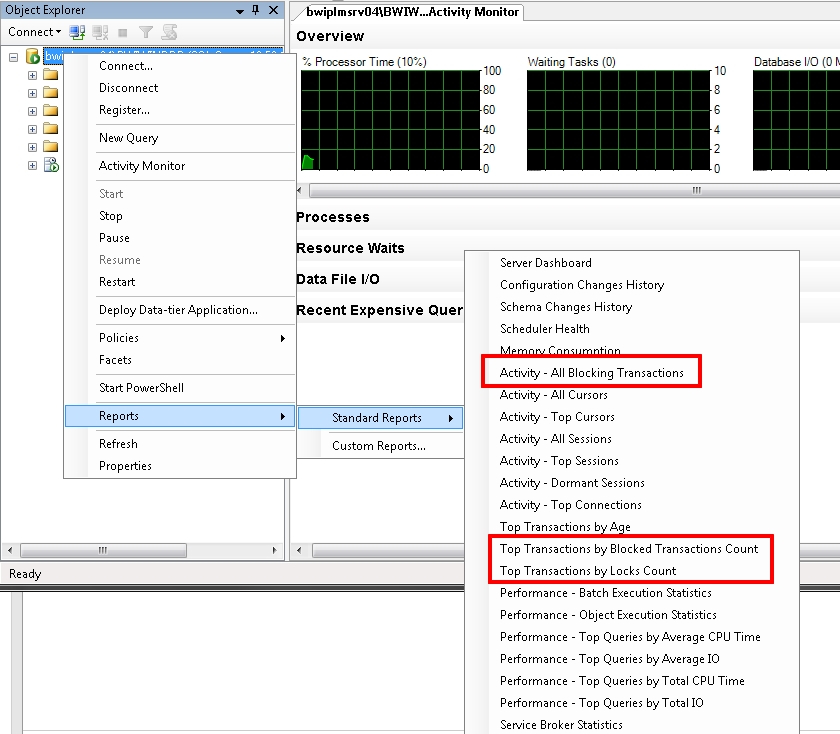
Upgrade Manger deletes/creates indices at its course of run. Did you notice any error in upgrade manager in this step?
Jun 09, 2015
11:10 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 09, 2015
11:10 AM
I Just discovered that server network card (Windchill 10.2 M030 virtualized) have a big amount of traffic (sometimes more than 200 MB!) when the worker is downloading a big assembly.
When this happens, the traffic from Windchill and Apache reverse proxy explode and Windchill become extremely slow.
If I shutdown the worker (Creo 3 M030), than all it's OK.
Marco
Jun 11, 2015
06:45 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 11, 2015
06:45 AM
We are still trying to fix our issue. We are finding some poorly optimized, both user & non-user initiated, SQL queries that can easily run for over an hour. When these queries run, the DB CPU spikes near 100% and all traffic seems to stop. We have also found that a WC restart takes close to 2 hours to bring it back to life because some of the startup queries can easily take over an hour to complete.
Jun 11, 2015
07:36 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 11, 2015
07:36 AM
Thanks for your info.
We have a different issue, I explain in my previous comment.
Have you noticed the same behavior?
Marco
Jun 11, 2015
08:05 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 11, 2015
08:05 AM
How big are your assemblies? Is 200 MB a reasonable download size? Is the CAD worker running on the same machine as your Windchill server?
Content download can be a stress factor for the server as the worker clients opens parallel connections for the download. You may get a clue looking at the server status page. Are there numbers in red (Maximum Concurrency)?
Jun 11, 2015
11:09 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 11, 2015
11:09 AM
Michael,
a brief summary.
We went from 10.1 M040 (single virtual server 16 GB + single virtual 8 GB CAD Worker with Creo 2 M140 and also Creo License Server) to 10.2 M030 (single virtual server 64 GB + single virtual CAD Worker with Creo 3 M030)
Because we are restructuring the contexts number (from more than 40 products to nearly 10), we are moving thousands of WTPart and EPMdoc and this caused republishing of thousands of objects.
To avoid this behavior, the first few days we stopped all publishing queues.
In the next days we moved CAD worker on the same server of Windchill, because of the network traffic generated between the two server.
The reason was the double publishing of the worker because of the Locale (see this article https://support.ptc.com/appserver/cs/view/solution.jsp?n=135042)
When we reactivated the worker, we experienced poor performance and I discovered what I described in my previous comment.
However it's quite incredible that, quadrupling the ram of the server, our users have this big pain working with Windchill.
Marco
Jun 18, 2015
01:58 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Jun 18, 2015
01:58 AM
Hi Marco,
what I experienced is that the CAD Worker might bring considerable load on the background server and the database doing all the dependency resolution and other things, even more when PDMLink and Server are running on fast machines. Creo 3.0 does downloads really multithreaded so there should be considerable traffic on the server. There will also be significant traffic between the system and the database.
So back to your problems:
- is there a direct relation of network traffic peaks on the server to the network traffic on the CAD worker?
- how many methodservers are configured on your system?
- what about the number of CPUs in the old and the new system?
- are there signs of problems in your webserver logs?
- what does your Server Status Page say about GC times and heap usage?
- when quadrupling the ram on the server did you do a new run of the Windchill Configuration Assistant?
- how is the storage connected - may there be a bottleneck when under heavy load?
Poor Windchill performance is typically caused by a heavy loaded database or insufficient resources for the Java VMs. If the problem is network related you should also encounter package drops and/or high retransmission rates.
Hope this helps to guide you to find a solution.
Aug 26, 2015
06:59 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Aug 26, 2015
06:59 AM
After upgrading to CPS04, we are back to functioning normally. Thank you everyone for you help.




