
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Please log in to access translation
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - Did you know you can set a signature that will be added to all your posts? Set it here! X
Translate the entire conversation x
Please log in to access translation
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
LeastSquaresFit in M13
Aug 04, 2010
06:58 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Aug 04, 2010
06:58 PM
LeastSquaresFit in M13
I am trying to understand the effect of accuracy value of "LeastSquaresFit" function.
My understanding is while increasing(narrow) accuracy, the error should
decrease. However, in the attached worksheet error is more with the accuracy of 10^-11
than with 10^-9.
Am I missing something here?
Any inputs on this would be great help. Thanks in advance
------
Refer to the attached worksheet which I have taken from Data analysis e-book.
4 REPLIES 4
Aug 05, 2010
12:39 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Aug 05, 2010
12:39 AM
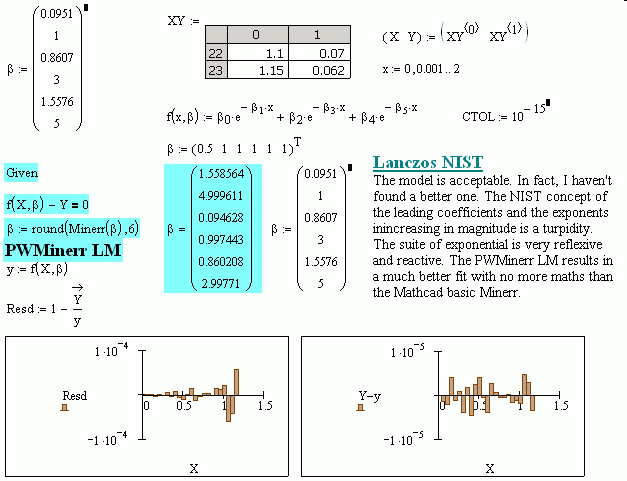
There is more to consider in curve fitting than thinking you are missing something. Clean data do not exist unless from a pure mathematical function. Collected data are subject to the digitization noise. A good figure is ± 0.001. Lanczos reveals ± 0.000005 ... a damn good lab equipment. What's ridiculous from NIST publication is the all lot of trailing zeros [non sense]. That their "statistical methods" arrive at the coefficients and exponents in increasing magnitude is erroneous. The exponential suite is very reflexive [not reflective] and reactive. The free raw PWMinerr arrives at a more realistic fit much faster and more economical in calculations. The PWMinerr was discovered after the DAEP was designed. About your "Acc" question, just forget it, rather go ahead with more advanced fitting techniques.
jmG
Aug 05, 2010
08:26 PM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Aug 05, 2010
08:26 PM
Thanks Jean,
I understand what you are saying..
So, increasing the acc does not necessarily reduce the error all the time and it depends on data itself.
Am I right? (I am just curious..)
Aug 06, 2010
01:15 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Aug 06, 2010
01:15 AM
Raj sharma wrote:
Thanks Jean,
I understand what you are saying..
So, increasing the acc does not necessarily reduce the error all the time and it depends on data itself.
Am I right? (I am just curious..)
Totally correct Raj. For years in this collab, nothing else than PWMinerr has been used and genfit completely abandoned. Most of the times Levenberg-Marquardt [LM] is the best option and generally the sole option. On very difficult models [not necessarily huge models], it will be Conjugate Gradient [CG]. Often we have to iterate manually... often again initialising the fit is very difficult and when too difficult it must be found manually. Mathcad has never failed fitting data. As a detail, I have done a lot of comparative fits between Mathcad PWMinerr and ORIGINLAB advanced statistical fitting that often fails, but not Mathcad.
Jean
Aug 06, 2010
08:08 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Please log in to access translation
Aug 06, 2010
08:08 AM
It seems to be a quirk of the iterative procedure. An iterative algorithm will not always converge to the same point. If you change the starting guesses, for example (try changing the first one to 0.7) it will converge to a slightly different solution. In a sense, there is some random error in the point at which it finishes iterating. The change in tolerance is too small to override this, and it happens that you get a larger residual with a smaller tolerance. If you change the tolerance to 10^-20 it will give you the smaller residual you expect.
As an aside, that function is not necessary for basic least squares fitting, although it is useful if you intend to use the optional parameters. For basic fitting just use minerr.





{kind=link}