
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
vector selection by increments
Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 18, 2009
03:00 AM
vector selection by increments
A new problem!
I wish to create a program which takes a user inputted increment and variable, say p, which is the index number of an x-value af a dataset, X.
The program should then create an array from a start point to (and including) an end point. The start point should be the index number of the corresponing x-value that is displaced half the increment before p and the end point is the index number of the corresponding x-value displaced half the increment after p.
Again, the information is technically confidential but I'll try and mock up some fake data and show you what I've tried so far.
(I'll attach it to a second post)
Thanks,
Neil
I wish to create a program which takes a user inputted increment and variable, say p, which is the index number of an x-value af a dataset, X.
The program should then create an array from a start point to (and including) an end point. The start point should be the index number of the corresponing x-value that is displaced half the increment before p and the end point is the index number of the corresponding x-value displaced half the increment after p.
Again, the information is technically confidential but I'll try and mock up some fake data and show you what I've tried so far.
(I'll attach it to a second post)
Thanks,
Neil
Labels:
- Labels:
-
Statistics_Analysis
49 REPLIES 49
Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 18, 2009
03:00 AM
Following your description would result in a 2-element array. Is that what you want?
Richard
Richard
Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 18, 2009
03:00 AM
Oh sorry! muddling my words again!
I just want the x values in the vector array - the range between and including the endpoints stated above.
Sorry for the confusion.
I have no time today but I'll hopefully get the mock up data and my progress tomorrow.
Thanks,
Neil
I just want the x values in the vector array - the range between and including the endpoints stated above.
Sorry for the confusion.
I have no time today but I'll hopefully get the mock up data and my progress tomorrow.
Thanks,
Neil
Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 18, 2009
03:00 AM
On 8/18/2009 12:11:03 PM, NSizzle wrote:
>I just want the x values in
>the vector array - the range
>between and including the
>endpoints stated above.
I still don't understand. I guess I'll wait for the worksheet.
Richard
>I just want the x values in
>the vector array - the range
>between and including the
>endpoints stated above.
I still don't understand. I guess I'll wait for the worksheet.
Richard
Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
.gif)
Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator

Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator

Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
Here is the mathcad sheet in 14 and mCAD 11 format with mock data included.
It's worth mentioning that the little program at the start with the rnd function in it is just to create this fake X-data - just ignore it.
Thanks,
Neil
It's worth mentioning that the little program at the start with the rnd function in it is just to create this fake X-data - just ignore it.
Thanks,
Neil
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
While your indexDEVtop and indexDEVbottom make no sense (you seem to be trying to use z as both an index and a data value, and have actually coded it as a function), the rest of it looks like you are just looking for a data value defined window. That is essentially what the first part of the generalized S-G smoothing does (although this code does not explicitly extract the data as such, but directly builds the coefficient arrays). i runs through the elements in the data array, j runs through the elements of the window around i.
__________________
� � � � Tom Gutman
__________________
� � � � Tom Gutman
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
As you could probably see from my attempts which made no sense, I'm not very literate in programming like this.
Could you just show me the bit that concerns my problem? I'm not really following what's going on there.
Thanks,
Neil
Could you just show me the bit that concerns my problem? I'm not really following what's going on there.
Thanks,
Neil
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
It's still not clear what you are trying to do. Let's start with the "little program" in the collapsed area.
Given a sorted vector of X values and two numbers xvalue1 and xvalue2 are you:
1) trying to find the index of the value in X that lies between xvalue1 and xvalue2, but is as close as possible to xvalue2?
2) trying to find the index of the value in X that lies as close as possible to xvalue2, but is greater than xvalue2 (this is what you are doing, but based on your description I think it's not what you want to do)?
3) trying to find the number of values in X that lie between xvalue1 and xvalue2?
4) something else?
And, again, arrays in Mathcad start at 0, not 1!
Richard
Given a sorted vector of X values and two numbers xvalue1 and xvalue2 are you:
1) trying to find the index of the value in X that lies between xvalue1 and xvalue2, but is as close as possible to xvalue2?
2) trying to find the index of the value in X that lies as close as possible to xvalue2, but is greater than xvalue2 (this is what you are doing, but based on your description I think it's not what you want to do)?
3) trying to find the number of values in X that lie between xvalue1 and xvalue2?
4) something else?
And, again, arrays in Mathcad start at 0, not 1!
Richard
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
Hi Richard,
for the program in the collapsed area I WAS going for 2). However I just included that to show what I mean in terms of the increment - a program that selects index values of the function.
EDIT: I should also mention that the "little program" does work.
Now however, I'm wanting to write a similar program whereby it goes through EACH POINT, say p, in the data set (in the example given, 15000 points) and selects the last point with respect to half the increment as you described it would select in 2). I want this program to do this in the other direction also.
So each new vector of numbers should have the point p somewhere in the middle of the data with the first and last values selected as such above.
Sorry if this is not more clear.
Thanks,
Neil
for the program in the collapsed area I WAS going for 2). However I just included that to show what I mean in terms of the increment - a program that selects index values of the function.
EDIT: I should also mention that the "little program" does work.
Now however, I'm wanting to write a similar program whereby it goes through EACH POINT, say p, in the data set (in the example given, 15000 points) and selects the last point with respect to half the increment as you described it would select in 2). I want this program to do this in the other direction also.
So each new vector of numbers should have the point p somewhere in the middle of the data with the first and last values selected as such above.
Sorry if this is not more clear.
Thanks,
Neil
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
On 8/19/2009 9:03:04 AM, NSizzle wrote:
>Hi Richard,
>for the program
>in the collapsed area I WAS
>going for 2). However I just
>included that to show what I
>mean in terms of the increment
>- a program that selects index
>values of the function.
If that's the case, you don't need xvalue1
>EDIT:
>I should also mention that the
>"little program" does
>work. Now however, I'm
>wanting to write a similar
>program whereby it goes
>through EACH POINT, say p, in
>the data set (in the example
>given, 15000 points)
It already goes through as much of the data vector as required to find the appropriate point. Do you mean you want to do this for every value of n, rather than every value of the data?
> and
>selects the last point with
>respect to half the increment
>as you described it would
>select in 2).
What? I don't understand what you mean.
> I want this
>program to do this in the
>other direction also.
What do you mean by "the other direction"?
>So each
>new vector of numbers should
>have the point p somewhere in
>the middle of the data with
>the first and last values
>selected as such above.
Each new vector? We would only generate one new vector: the vector of indices.
Switching to a different part of your description of the problem, are you trying to generate a vector of vectors, where each sub-vector contains the indices of all the points in the data that lie between n-inc/2 and n+inc/2? There would be N such subvectors, and n would range between 0 and N-1 in steps of inc.
Richard
>Hi Richard,
>for the program
>in the collapsed area I WAS
>going for 2). However I just
>included that to show what I
>mean in terms of the increment
>- a program that selects index
>values of the function.
If that's the case, you don't need xvalue1
>EDIT:
>I should also mention that the
>"little program" does
>work. Now however, I'm
>wanting to write a similar
>program whereby it goes
>through EACH POINT, say p, in
>the data set (in the example
>given, 15000 points)
It already goes through as much of the data vector as required to find the appropriate point. Do you mean you want to do this for every value of n, rather than every value of the data?
> and
>selects the last point with
>respect to half the increment
>as you described it would
>select in 2).
What? I don't understand what you mean.
> I want this
>program to do this in the
>other direction also.
What do you mean by "the other direction"?
>So each
>new vector of numbers should
>have the point p somewhere in
>the middle of the data with
>the first and last values
>selected as such above.
Each new vector? We would only generate one new vector: the vector of indices.
Switching to a different part of your description of the problem, are you trying to generate a vector of vectors, where each sub-vector contains the indices of all the points in the data that lie between n-inc/2 and n+inc/2? There would be N such subvectors, and n would range between 0 and N-1 in steps of inc.
Richard
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
On 8/19/2009 5:01:09 AM, NSizzle wrote:
>Here is the mathcad sheet in
>14 and mCAD 11 format with
>mock data included.
>
>It's worth mentioning that the
>little program at the start
>with the rnd function in it is
>just to create this fake
>X-data - just ignore it.
>
>Thanks,
>Neil
_______________________________
Here I am trying to get a program that goes through this data point by point that returns all values within half the increment on each side of the current point.
.............................
How can you get � increment that does not exist ?
Your noisy vector does nothing trying to understand what you don't express by a real data set. Noise on Cartesian X , we don't care whereas the fitting methods cope with that.
Scrap all what you have done in your work sheet, return my input and tell what you are trying to do. If you stick with what you don't understand, you will probably have no answer, ever. What I mean is, if you don't like my vector, put yours, but don't put a random one again because random collection don't exist unless for specific purpose.
If you want a data explorer, would be lot simpler.
jmG
>Here is the mathcad sheet in
>14 and mCAD 11 format with
>mock data included.
>
>It's worth mentioning that the
>little program at the start
>with the rnd function in it is
>just to create this fake
>X-data - just ignore it.
>
>Thanks,
>Neil
_______________________________
Here I am trying to get a program that goes through this data point by point that returns all values within half the increment on each side of the current point.
.............................
How can you get � increment that does not exist ?
Your noisy vector does nothing trying to understand what you don't express by a real data set. Noise on Cartesian X , we don't care whereas the fitting methods cope with that.
Scrap all what you have done in your work sheet, return my input and tell what you are trying to do. If you stick with what you don't understand, you will probably have no answer, ever. What I mean is, if you don't like my vector, put yours, but don't put a random one again because random collection don't exist unless for specific purpose.
If you want a data explorer, would be lot simpler.
jmG
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
I'm not very good at describing my problems 😛
I'll try and do it as simply as I can.
Let's say I have an array/vector, X, like this
> 0
0 1
1 3
2 5
3 7.5
4 9.5
5 11
6 12
7 15
8 17
9 19
lets say I want to create a vector with point 4(9.5), let's call it p4, being the subject.
Let's say the increment is 7.
The program should now return closest points 7/2 (increment/2) either side of 9.5(p4).
9.5 + - 7/2 = 6 and 13
The program should now find the first point less than or equal to 6 and the first point greater than or equal to 13.
So, in this case, the following vector should be returned:
> 0
0 5
1 7.5
2 9.5
3 11
4 12
5 15
now, for point 5(11), let's call it p5, using the same increment we find
11 + - 7/2 = 7.5 and 14.5
So, for p5 (11), the program should return this vector:
> 0
0 7.5
1 9.5
2 11
3 12
4 15
Notice that the vectors aren't always the same length, and that the don't necessarily end on differnt points for the previous points respective vector.
I hope this clarifies it.
Thanks,
Neil
I'll try and do it as simply as I can.
Let's say I have an array/vector, X, like this
> 0
0 1
1 3
2 5
3 7.5
4 9.5
5 11
6 12
7 15
8 17
9 19
lets say I want to create a vector with point 4(9.5), let's call it p4, being the subject.
Let's say the increment is 7.
The program should now return closest points 7/2 (increment/2) either side of 9.5(p4).
9.5 + - 7/2 = 6 and 13
The program should now find the first point less than or equal to 6 and the first point greater than or equal to 13.
So, in this case, the following vector should be returned:
> 0
0 5
1 7.5
2 9.5
3 11
4 12
5 15
now, for point 5(11), let's call it p5, using the same increment we find
11 + - 7/2 = 7.5 and 14.5
So, for p5 (11), the program should return this vector:
> 0
0 7.5
1 9.5
2 11
3 12
4 15
Notice that the vectors aren't always the same length, and that the don't necessarily end on differnt points for the previous points respective vector.
I hope this clarifies it.
Thanks,
Neil
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
On 8/19/2009 11:16:42 AM, NSizzle wrote:
>I'm not very good at
>describing my problems 😛
>
>I'll try and do it as simply
>as I can.
>
>Let's say I have an
>array/vector, X, like this
>
>> 0
>0 1
>1 3
>2 5
>3 7.5
>4 9.5
>5 11
>6 12
>7 15
>8 17
>9 19
>
>lets say I want to create a
>vector with point 4(9.5),
>let's call it p4, being the
>subject.
>
>Let's say the increment is 7.
>
>The program should now return
>closest points 7/2
>(increment/2) either side of
>9.5(p4).
>
>9.5 + - 7/2 = 6 and 13
>
>The program should now find
>the first point less than or
>equal to 6 and the first point
>greater than or equal to 13.
>
>So, in this case, the
>following vector should be
>returned:
>
>> 0
>0 5
>1 7.5
>2 9.5
>3 11
>4 12
>5 15
>
>now, for point 5(11), let's
>call it p5, using the same
>increment we find
>
>11 + - 7/2 = 7.5 and 14.5
>
>So, for p5 (11), the program
>should return this vector:
>
>> 0
>0 7.5
>1 9.5
>2 11
>3 12
>4 15
>
>
>
>Notice that the vectors aren't
>always the same length, and
>that the don't necessarily end
>on differnt points for the
>previous points respective
>vector.
>
>
>
>I hope this clarifies it.
>
>
>Thanks,
>Neil
Seems like that's what the file I posted does.
TTFN,
Eden
>I'm not very good at
>describing my problems 😛
>
>I'll try and do it as simply
>as I can.
>
>Let's say I have an
>array/vector, X, like this
>
>> 0
>0 1
>1 3
>2 5
>3 7.5
>4 9.5
>5 11
>6 12
>7 15
>8 17
>9 19
>
>lets say I want to create a
>vector with point 4(9.5),
>let's call it p4, being the
>subject.
>
>Let's say the increment is 7.
>
>The program should now return
>closest points 7/2
>(increment/2) either side of
>9.5(p4).
>
>9.5 + - 7/2 = 6 and 13
>
>The program should now find
>the first point less than or
>equal to 6 and the first point
>greater than or equal to 13.
>
>So, in this case, the
>following vector should be
>returned:
>
>> 0
>0 5
>1 7.5
>2 9.5
>3 11
>4 12
>5 15
>
>now, for point 5(11), let's
>call it p5, using the same
>increment we find
>
>11 + - 7/2 = 7.5 and 14.5
>
>So, for p5 (11), the program
>should return this vector:
>
>> 0
>0 7.5
>1 9.5
>2 11
>3 12
>4 15
>
>
>
>Notice that the vectors aren't
>always the same length, and
>that the don't necessarily end
>on differnt points for the
>previous points respective
>vector.
>
>
>
>I hope this clarifies it.
>
>
>Thanks,
>Neil
Seems like that's what the file I posted does.
TTFN,
Eden
Aug 20, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 20, 2009
03:00 AM
I don't think it does. In your post you have the increment as 5 but it selects points much larger than 2.5 away.
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
... and you couldn't plug that in a work sheet (the 2 columns array) !
If you stick with your idea and don't read the replies, no point visiting for help because I done it all in parts since my 1rst reply, except that here you have it apparently as you should have in your first post.

Anyway: done.
It might be possible to compact all in a single programme.
jmG
If you stick with your idea and don't read the replies, no point visiting for help because I done it all in parts since my 1rst reply, except that here you have it apparently as you should have in your first post.
Anyway: done.
It might be possible to compact all in a single programme.
jmG
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
>Seems like that's what the file I posted does.< [Eden]
__________________________
Yes, it does differently. That's why I showed the conditional interval for selecting which bottle of milk out of two. Below Marlett is more than wanted, in case. I can see another way of doing, but Neil must come back with a completed wish list.
jmG
__________________________
Yes, it does differently. That's why I showed the conditional interval for selecting which bottle of milk out of two. Below Marlett is more than wanted, in case. I can see another way of doing, but Neil must come back with a completed wish list.
jmG
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
On 8/19/2009 11:16:42 AM, NSizzle wrote:
>I'm not very good at
>describing my problems 😛
>
>I'll try and do it as simply
>as I can.
>
>Let's say I have an
>array/vector, X, like this
>
...
Here's my contribution. Please notice I can't see the other sheets 'cause I'm using an old version of MC. So if someone posted a solution, please disregard this post.
In this program I used two index (i & m) for clarity.

The conditional (m>=ORIGIN) .AND. (Xm>=Xlow) works well in my machine 'cause my version of MC don't evaluates all the conditional if the first clause is false (in this case). I don't know if that have changed in newer versions.
Saludos,
Al
P.S. I edited this post to correct one error in the program.
>I'm not very good at
>describing my problems 😛
>
>I'll try and do it as simply
>as I can.
>
>Let's say I have an
>array/vector, X, like this
>
...
Here's my contribution. Please notice I can't see the other sheets 'cause I'm using an old version of MC. So if someone posted a solution, please disregard this post.
In this program I used two index (i & m) for clarity.
The conditional (m>=ORIGIN) .AND. (Xm>=Xlow) works well in my machine 'cause my version of MC don't evaluates all the conditional if the first clause is false (in this case). I don't know if that have changed in newer versions.
Saludos,
Al
P.S. I edited this post to correct one error in the program.
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
Grrrr... sorry, because I'm used to work with ORIGIN = 1, there is still one more bug in the program. The first line should read:
N <- last(X)
to work with other settings of ORIGIN. Also the range variable used for the fake data should start in ORIGIN rather than 1.
Saludos,
Al
N <- last(X)
to work with other settings of ORIGIN. Also the range variable used for the fake data should start in ORIGIN rather than 1.
Saludos,
Al
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
Al,
There are some contradiction in what Neil wants. But with all the replies, he can surely come back with more accurate "wanted". My last help is below Marlett, as far as the example in hand.
jmG
There are some contradiction in what Neil wants. But with all the replies, he can surely come back with more accurate "wanted". My last help is below Marlett, as far as the example in hand.
jmG
Aug 19, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 19, 2009
03:00 AM
On 8/19/2009 3:49:02 PM, jmG wrote:
>Al,
>
>There are some contradiction
>in what Neil wants. But with
>all the replies, he can surely
>come back with more accurate
>"wanted"...
...
Agree. Here's my last contribution, inspired in your post, and in a more "Mathcad like" style of programming. However the first version is more friendly in memory usage.

Saludos,
Al
>Al,
>
>There are some contradiction
>in what Neil wants. But with
>all the replies, he can surely
>come back with more accurate
>"wanted"...
...
Agree. Here's my last contribution, inspired in your post, and in a more "Mathcad like" style of programming. However the first version is more friendly in memory usage.
Saludos,
Al
Aug 20, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 20, 2009
03:00 AM
Al2000: from the first line of your code, doesn't that suggest that it would always return "NA"?
#EDIT: Sorry, I understand now.
jmG: Sorry, you're right. I was just getting sonfused by what your code actually did. I think I get it now. And you needn't have augmented it, the numbers down the left hand side of my last post was just to represent the value's index number.
Edit: also jmG, what does this mean? (SEE PICTURE) you say above it that it depends on the data, but how? If I tell you I currently have 15000 datapoints but this should encompass all ascending datasets would that give you an indication as to what I should enter here
#EDIT: Sorry, I understand now.
jmG: Sorry, you're right. I was just getting sonfused by what your code actually did. I think I get it now. And you needn't have augmented it, the numbers down the left hand side of my last post was just to represent the value's index number.
Edit: also jmG, what does this mean? (SEE PICTURE) you say above it that it depends on the data, but how? If I tell you I currently have 15000 datapoints but this should encompass all ascending datasets would that give you an indication as to what I should enter here
Aug 20, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 20, 2009
03:00 AM
By the way, Al2000's method seems more applicable to me.
No offence jmG but I don't know what's going on in yours
No offence jmG but I don't know what's going on in yours
Aug 20, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 20, 2009
03:00 AM
I've been able to implement Al's second last worksheet and it does what I want it to do! great!
However, how do I to it for:
middle:=q
q:=ORIGIN..Last(X)?
Thanks
Neil
By this I mean it works when you manually put in a point, but how do you do it for every point in X?
In the same fashion as Ln in the attachment in my third post.
However, how do I to it for:
middle:=q
q:=ORIGIN..Last(X)?
Thanks
Neil
By this I mean it works when you manually put in a point, but how do you do it for every point in X?
In the same fashion as Ln in the attachment in my third post.
Aug 20, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 20, 2009
03:00 AM
Ok, ignore my last post.
I've encountered a problem. Using Al's second last posted sheet it works until the window width would overstep the last point and then it fails.
Is there a way of making the program just stop the window at the last point and continue onto the next Middle point?
Thanks,
Neil
I've encountered a problem. Using Al's second last posted sheet it works until the window width would overstep the last point and then it fails.
Is there a way of making the program just stop the window at the last point and continue onto the next Middle point?
Thanks,
Neil
Aug 20, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 20, 2009
03:00 AM
On 8/20/2009 6:10:47 AM, NSizzle wrote:
>I've been able to implement
>Al's second last worksheet and
>it does what I want it to do!
>great!
However, how do I to
>it
>for:
middle:=q
q:=ORIGIN..Las
>t(X)?
...
Peace,
Al
>I've been able to implement
>Al's second last worksheet and
>it does what I want it to do!
>great!
However, how do I to
>it
>for:
middle:=q
q:=ORIGIN..Las
>t(X)?
...
Peace,
Al
Aug 20, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 20, 2009
03:00 AM
On 8/20/2009 5:58:11 AM, NSizzle wrote:
>By the way, Al2000's method
>seems more applicable to me.
>
>No offence jmG but I don't
>know what's going on in yours
______________________________
Neil,
What I have done for you is a complete project, including the plot highlight. The auctioneer c(x) is one of many variants in Mathcad, it is bread & butter, that you can conserve or discard. At the end, ExtractWidow(X,9.5,3.5) = "NA" ... if you think it does what you want, fine... then your demo is incorrect. You can't have it both ways: right/wrong. The other collab you didn't consider is Eden reply, why not a simple submatrix ? The problem is that we have no idea of what you have in mind and as long as you will not scope your project, things are not in gear. Why do you think such a monkey business ExtractWidow(X,middle,width) would replace the Mathcad native auctioneer function c(x) ?
The problem is on your side, i.e: scope your project. Do you have some work sheet in reference that is to be adapted, any other piece of information that would help ? Blabla is never enough and too much. Dismantling prefabricated ideas is the hardest part in this collab. However, in 10 years, this collaboratory has never failed.
jmG
>By the way, Al2000's method
>seems more applicable to me.
>
>No offence jmG but I don't
>know what's going on in yours
______________________________
Neil,
What I have done for you is a complete project, including the plot highlight. The auctioneer c(x) is one of many variants in Mathcad, it is bread & butter, that you can conserve or discard. At the end, ExtractWidow(X,9.5,3.5) = "NA" ... if you think it does what you want, fine... then your demo is incorrect. You can't have it both ways: right/wrong. The other collab you didn't consider is Eden reply, why not a simple submatrix ? The problem is that we have no idea of what you have in mind and as long as you will not scope your project, things are not in gear. Why do you think such a monkey business ExtractWidow(X,middle,width) would replace the Mathcad native auctioneer function c(x) ?
The problem is on your side, i.e: scope your project. Do you have some work sheet in reference that is to be adapted, any other piece of information that would help ? Blabla is never enough and too much. Dismantling prefabricated ideas is the hardest part in this collab. However, in 10 years, this collaboratory has never failed.
jmG
Aug 20, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 20, 2009
03:00 AM
Al: for that program, on my pc it claims that ExtractWindow2(X,5,0.5)= needs to be a scalar (an error in red)
The lengthier looking program you submitted before, ExtractWindow I think, worked fine though.
Maybe you could re-submit the new revised edition in the other format?
Also do you know a way of resolving the issue mentioned in my previous post?
jmG: Sorry jmG, I think there is a loss of communication between us because I don't really understand what you meant in the first part of your last post.
By the way, I meant a SINGLE column vector as the X data - not two collumns. On my post where I listed the example data the zero at the top represented the column as displayed in mathCad and the numbers from 0-9 down the left hand sede represented the indices of the single column vector, X.
Kind regards,
Neil
The lengthier looking program you submitted before, ExtractWindow I think, worked fine though.
Maybe you could re-submit the new revised edition in the other format?
Also do you know a way of resolving the issue mentioned in my previous post?
jmG: Sorry jmG, I think there is a loss of communication between us because I don't really understand what you meant in the first part of your last post.
By the way, I meant a SINGLE column vector as the X data - not two collumns. On my post where I listed the example data the zero at the top represented the column as displayed in mathCad and the numbers from 0-9 down the left hand sede represented the indices of the single column vector, X.
Kind regards,
Neil


.gif){kind=link}
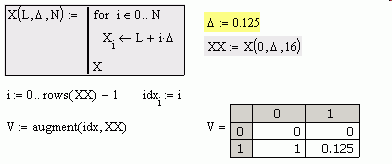{kind=link}
{kind=link}
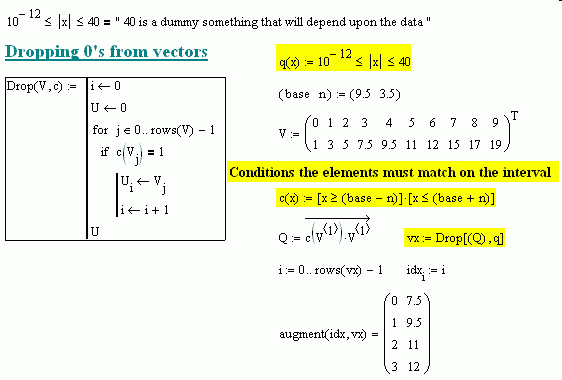{kind=link}
{kind=link}
{kind=link}