
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - Need to share some code when posting a question or reply? Make sure to use the "Insert code sample" menu option. Learn more! X
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Verhulst Curve Fit
Sep 09, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 09, 2009
03:00 AM
Verhulst Curve Fit
Collab,
We recently performed an experiment which is sort of the opposite of Verhulst. A special cell culture, suspended in an appropriate media, was held at a constant temperature.
The study was to analyze the rate at which cell death occurred at different temperatures.
For this study, the cell population's viability was sampled at 6 minute intervals up to 2 hours.
The resulting curve appears somewhat like an inverted Verhulst curve.
Using a model from an earlier post by Jean showing the Verhulst model, I tweaked the coefficients to get a best visual match.
Apparently, Verhulst is not the best model to fit my data.
Does Jean or any Collab have a suggestion for a better fit model?
Thanks,
Art
We recently performed an experiment which is sort of the opposite of Verhulst. A special cell culture, suspended in an appropriate media, was held at a constant temperature.
The study was to analyze the rate at which cell death occurred at different temperatures.
For this study, the cell population's viability was sampled at 6 minute intervals up to 2 hours.
The resulting curve appears somewhat like an inverted Verhulst curve.
Using a model from an earlier post by Jean showing the Verhulst model, I tweaked the coefficients to get a best visual match.
Apparently, Verhulst is not the best model to fit my data.
Does Jean or any Collab have a suggestion for a better fit model?
Thanks,
Art
Labels:
- Labels:
-
Statistics_Analysis
32 REPLIES 32
Sep 09, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 09, 2009
03:00 AM
Salut Art, long time you didn't visit the collab !
By inspection, there are two phenomenons and probably two segments. Will try tonight but no guaranty for a single function, OK, single in two segments. But what we can do for sure is populate the data set in order to get an export table for interpolation.
Oh ! here is a damned good fit from the tool box. Taking into account some global incertitude in the measurements, you could probably "declare the function".
Jean
By inspection, there are two phenomenons and probably two segments. Will try tonight but no guaranty for a single function, OK, single in two segments. But what we can do for sure is populate the data set in order to get an export table for interpolation.
Oh ! here is a damned good fit from the tool box. Taking into account some global incertitude in the measurements, you could probably "declare the function".
Jean
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
Salut Jean!
I played around with logistic fits from Origin - no good. Maybe you have a better solution.
Art
I played around with logistic fits from Origin - no good. Maybe you have a better solution.
Art
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 10:49:32 AM, ArtZ wrote:
>Salut Jean!
>
>I played around with logistic
>fits from Origin - no good.
>Maybe you have a better
>solution.
>
>Art
______________________________
You mean the fit at the end of your work sheet ?
Here is a 5/5 rational fraction.
f(x) is the continued fraction expansion of the rational above. Can't get any closer to your data points. There is a way to patch the logistic but that will be a band aid doing same but worst than the rational fraction.
Hope you like that one better , Art !
Jean
>Salut Jean!
>
>I played around with logistic
>fits from Origin - no good.
>Maybe you have a better
>solution.
>
>Art
______________________________
You mean the fit at the end of your work sheet ?
Here is a 5/5 rational fraction.
f(x) is the continued fraction expansion of the rational above. Can't get any closer to your data points. There is a way to patch the logistic but that will be a band aid doing same but worst than the rational fraction.
Hope you like that one better , Art !
Jean
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
That is too much work to do to get a good fit. Here, the Lang.mcd MC11.MO worksheet takes the same raw data and develops a more perfect fit with easily arranged parameters on a simple Thiele model. An error on your continued fraction of 0.092 can be reduced to 0.001 in a few keystrokes of the CtrlF9 command.
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
Going through all the points would be a technical mistake as it would reproduce the unavoidable errors on the data collection. The continued fraction is in the range of 0.002, better or in the range of the digitization + other sources. Fitting still means "fitting", and fitting can't be better than the uncertain data.

jmG
jmG
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
Yes, that is for your model. I used a higher degree Thiele model that gave closer real fits at all points, to be sure, but the important idea was that I arranged for initial guesses in the Minerr process to come from a random slate of values instead of a "hit & run" single guess for all parameters. Automatic and easy to run is my set up.
I sometimes wonder if Ctrl+F9 after an initial run of Minerr uses the found values of the coefficents as new starting guesses. The time on the first run is longer than on succeeding runs. Was that extra time needed to prepare the stack for addresses of numbers and program run and then anything after that used the same memory map.
I sometimes wonder if Ctrl+F9 after an initial run of Minerr uses the found values of the coefficents as new starting guesses. The time on the first run is longer than on succeeding runs. Was that extra time needed to prepare the stack for addresses of numbers and program run and then anything after that used the same memory map.
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
>I sometimes wonder if Ctrl+F9 after an initial run of Minerr uses the found values of the coefficents as new starting guesses<.
___________________________
It does not use the precalculated values. PWMinerr is a single shot. Your setup will never work, why ? because no matter how the guesses from random, they will always be of too high value for the high order monomials. If you modify Lang2 (I did), for it to be a true rational with leading 1 in the denominator and initialise all the vector of CT with 0's, that will work. The leading 1 reduces the number of operations in numerical approximations, as well it has a "numerical cleaning" property (minimizes error propagation). Also, make sure you have LM (you had QN in the Minerr options). You can apply a 2nd run (refined fit).
All that was embedded in the Robert GenfitMatrix at the time of the DAEP. It never failed to me, and fully automatic, no guess needed, just plug the num/denom order and watch the fit. For the final export, the coefficients must be saved in file and press F9 on READPRN. Also, set the two options in grey images. Your approach as I modified, produces the same resulting fit.
jmG
___________________________
It does not use the precalculated values. PWMinerr is a single shot. Your setup will never work, why ? because no matter how the guesses from random, they will always be of too high value for the high order monomials. If you modify Lang2 (I did), for it to be a true rational with leading 1 in the denominator and initialise all the vector of CT with 0's, that will work. The leading 1 reduces the number of operations in numerical approximations, as well it has a "numerical cleaning" property (minimizes error propagation). Also, make sure you have LM (you had QN in the Minerr options). You can apply a 2nd run (refined fit).
All that was embedded in the Robert GenfitMatrix at the time of the DAEP. It never failed to me, and fully automatic, no guess needed, just plug the num/denom order and watch the fit. For the final export, the coefficients must be saved in file and press F9 on READPRN. Also, set the two options in grey images. Your approach as I modified, produces the same resulting fit.
jmG
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
Yes, you are right, jmG. I always thought that the Guesses would initialize the Minerr as a starting point. I ran through both these worksheets quite a few times and found changing the random guesses didn't make any difference.
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
On 9/10/2009 11:41:16 PM, study wrote:
>Yes, you are right, jmG. I
>always thought that the
>Guesses would initialize the
>Minerr as a starting point. I
>ran through both these
>worksheets quite a few times
>and found changing the random
>guesses didn't make any
>difference.
______________________________
That's right, if instead of using PWMinerr LM you would use genfit, same results because genfit is LM. The fact you have 1 in the denom, the matter is to null the monomials in the denom and get the two first monomials of the num to cross the data set. On some data sets, the Robert genfit matrix failed because of the general initialisation couldn't cross the data set. The fit was then via genfit and get the initial to cross the data set of huge size numbers that created numerical instability.
Quite a monkey business fitting data, is it !
jmG
>Yes, you are right, jmG. I
>always thought that the
>Guesses would initialize the
>Minerr as a starting point. I
>ran through both these
>worksheets quite a few times
>and found changing the random
>guesses didn't make any
>difference.
______________________________
That's right, if instead of using PWMinerr LM you would use genfit, same results because genfit is LM. The fact you have 1 in the denom, the matter is to null the monomials in the denom and get the two first monomials of the num to cross the data set. On some data sets, the Robert genfit matrix failed because of the general initialisation couldn't cross the data set. The fit was then via genfit and get the initial to cross the data set of huge size numbers that created numerical instability.
Quite a monkey business fitting data, is it !
jmG
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 10:49:32 AM, ArtZ wrote:
>Salut Jean!
>
>I played around with logistic
>fits from Origin - no good.
>Maybe you have a better
>solution.
What is the end goal here? Once you have the fit, what are you going to do with it?
Richard
>Salut Jean!
>
>I played around with logistic
>fits from Origin - no good.
>Maybe you have a better
>solution.
What is the end goal here? Once you have the fit, what are you going to do with it?
Richard
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
All,
Thanks for the help. Jean's 5th order fit and Theodore's Thiele seem more complex than the physical model, though the fit to the data is good.
Richard's point, what will I do with the fit is a good question. It seems that there may be a predictor of the the cell death response based on time and temperature. We know the kinetic rate constants affecting enzyme deactivation are different for different cells based other similar experiments. Just hoping for a way to extrapolate a little.
Attached is a fit that I did using a 3 parameter logistic curve. The residuals aren't not as nice as Jean's but may be usable.
Art
Thanks for the help. Jean's 5th order fit and Theodore's Thiele seem more complex than the physical model, though the fit to the data is good.
Richard's point, what will I do with the fit is a good question. It seems that there may be a predictor of the the cell death response based on time and temperature. We know the kinetic rate constants affecting enzyme deactivation are different for different cells based other similar experiments. Just hoping for a way to extrapolate a little.
Attached is a fit that I did using a 3 parameter logistic curve. The residuals aren't not as nice as Jean's but may be usable.
Art
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
The worksheet I gave enables simnple caculations with the RR(CT,vx) command. I have copied jmG's f(x) residuals and posted mine just below. They are smaller.
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
Theodore,
It seems MinErr does always converge. I ran crtl F9 numerous times and cannot get anything better than this. See attached screen shot.
Art
It seems MinErr does always converge. I ran crtl F9 numerous times and cannot get anything better than this. See attached screen shot.
Art
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 2:04:36 PM, ArtZ wrote:
>Richard's point, what will I
>do with the fit is a good
>question. It seems that there
>may be a predictor of the the
>cell death response based on
>time and temperature. We know
>the kinetic rate constants
>affecting enzyme deactivation
>are different for different
>cells based other similar
>experiments. Just hoping for a
>way to extrapolate a little.
OK. A couple more questions.
Extrapolate in which direction? Time, or temperature? If it's temperature (and arguably even if it's time) you should be fitting a surface to multiple sets of data taken at different temperatures. Do you have data for other temperatures?
The first 8 points are all 100. Did you really have no cell death at all for the first 40 minutes, followed by a sudden decline, or is time zero not really time zero?
Richard
>Richard's point, what will I
>do with the fit is a good
>question. It seems that there
>may be a predictor of the the
>cell death response based on
>time and temperature. We know
>the kinetic rate constants
>affecting enzyme deactivation
>are different for different
>cells based other similar
>experiments. Just hoping for a
>way to extrapolate a little.
OK. A couple more questions.
Extrapolate in which direction? Time, or temperature? If it's temperature (and arguably even if it's time) you should be fitting a surface to multiple sets of data taken at different temperatures. Do you have data for other temperatures?
The first 8 points are all 100. Did you really have no cell death at all for the first 40 minutes, followed by a sudden decline, or is time zero not really time zero?
Richard
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
I think, that here the model nonisothermal chemical kinetics is quite pertinent. Look an attachment.
Viktor
Viktor
Viktor
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
On 9/11/2009 4:52:54 AM, vikkor wrote:
>I think, that here the model
>nonisothermal chemical
>kinetics is quite pertinent.
>Look an attachment.
>
>Viktor
____________________________
No doubt you got something !
I think Art is at Mathcad 2001i
jmG
>I think, that here the model
>nonisothermal chemical
>kinetics is quite pertinent.
>Look an attachment.
>
>Viktor
____________________________
No doubt you got something !
I think Art is at Mathcad 2001i
jmG
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
Viktor,
Thanks! That's great. I can't view the residual plot (error: all evaluations resulted in an error or complex result) but I can tell from y axis limits that the residuals are small. 🙂
Is it possible to find a closed form solution to Viktor's diff eq? That would be helpful.
In regards to Richard's comments. Yes, I would like to be able to extrapolate for both time and temperature to compare with actual data with different times and temperatures.
In a typical reaction process, thermally active reactants jump an activation barrier to form products. The collision theory description of first order bimolecular reaction kinetics holds that the reactants are activated by collisions: n* are activated out of n total molecules. The probability of activation is:
n*/n = A*exp(-(E/RT))
where A is the frequency factor in 1/s, R is the universal gas constant (8.314 J/mole*K) and T is absolute temperture (K) and E is the activation energy barrier in J/mole.
Richard, sorry for the long answer, but yes, until the reactants exceed the energy barrier, cell death is not probable.
Thanks All,
Art
Thanks! That's great. I can't view the residual plot (error: all evaluations resulted in an error or complex result) but I can tell from y axis limits that the residuals are small. 🙂
Is it possible to find a closed form solution to Viktor's diff eq? That would be helpful.
In regards to Richard's comments. Yes, I would like to be able to extrapolate for both time and temperature to compare with actual data with different times and temperatures.
In a typical reaction process, thermally active reactants jump an activation barrier to form products. The collision theory description of first order bimolecular reaction kinetics holds that the reactants are activated by collisions: n* are activated out of n total molecules. The probability of activation is:
n*/n = A*exp(-(E/RT))
where A is the frequency factor in 1/s, R is the universal gas constant (8.314 J/mole*K) and T is absolute temperture (K) and E is the activation energy barrier in J/mole.
Richard, sorry for the long answer, but yes, until the reactants exceed the energy barrier, cell death is not probable.
Thanks All,
Art
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
>Yes, I would like to be able to extrapolate for both time and temperature to compare with actual data with different times and temperatures. <<br> ________________________
Then with my very first formula: YES !
With the rational fraction: should be !
Approximating Viktor, goes back to the approximation of the original data set !!!
The problem is the linear segment on 8 points. Nothing goes on until some smart starts the chrono ... Get the "smart" starts the collection synchronized to avoid the discontinuous part. The real part of the experiment seems exp rather than sigmoidal. Not sure either, that if the data shifts the Viktor fit will still be valid ?
jmG
Then with my very first formula: YES !
With the rational fraction: should be !
Approximating Viktor, goes back to the approximation of the original data set !!!
The problem is the linear segment on 8 points. Nothing goes on until some smart starts the chrono ... Get the "smart" starts the collection synchronized to avoid the discontinuous part. The real part of the experiment seems exp rather than sigmoidal. Not sure either, that if the data shifts the Viktor fit will still be valid ?
jmG
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
Jean,
This gets circular doesn't it. It definitely appears that there's not a simple approximation of Viktor's diff eq solution.
What Viktor's solution does tell me (I think) is that some form of Verhulst is the answer.
I don't see a way to directly integrate Viktor's diff eq, do you?
You rational fraction scare me!
Art
This gets circular doesn't it. It definitely appears that there's not a simple approximation of Viktor's diff eq solution.
What Viktor's solution does tell me (I think) is that some form of Verhulst is the answer.
I don't see a way to directly integrate Viktor's diff eq, do you?
You rational fraction scare me!
Art
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
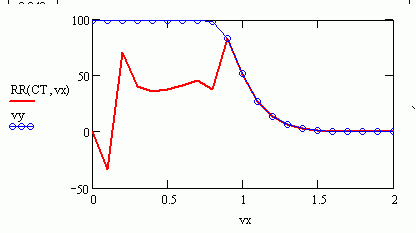
I don't know whose rational fraction you meant. I have simplified mine, so here it is in MC11 from MC14. Use RR(CT,u) to calculate ANY point (u).
Sep 12, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 12, 2009
03:00 AM
There is no point in trying exotic curve fitting on this. The simple lspline will do it very accurately.
Sep 12, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 12, 2009
03:00 AM
On 9/12/2009 1:43:07 AM, study wrote:
>There is no point in trying
>exotic curve fitting on this.
>The simple lspline will do it
>very accurately.
_____________________________
OK ! but like usual, it seems Art wants a function that will execute on low level computing machinery Excel for instance. The other point is that the collection is not exact and lpcspline doe no good. How can 3 digits result from real experiments. The point 99.03 is NFG ! That I maintain. Spline for spline, I have added the polyline but not tabulated the export. Like usual, we are pedalling in butter because of the data collection.
All (if not) data fitting done in this collab [100's], they all point back to the data collection and the unavoidable inaccuracy, and unknown forgery by unknown.
jmG
>There is no point in trying
>exotic curve fitting on this.
>The simple lspline will do it
>very accurately.
_____________________________
OK ! but like usual, it seems Art wants a function that will execute on low level computing machinery Excel for instance. The other point is that the collection is not exact and lpcspline doe no good. How can 3 digits result from real experiments. The point 99.03 is NFG ! That I maintain. Spline for spline, I have added the polyline but not tabulated the export. Like usual, we are pedalling in butter because of the data collection.
All (if not) data fitting done in this collab [100's], they all point back to the data collection and the unavoidable inaccuracy, and unknown forgery by unknown.
jmG
Sep 12, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 12, 2009
03:00 AM
Art, here is my reconciliation (end of the attached):
Run Viktor fit DE system for each new data set and get an export from the rational. Attached is your data set + Viktor 1000 points fitted rational. The rational will run on Excel, no sweat !
Jean
Run Viktor fit DE system for each new data set and get an export from the rational. Attached is your data set + Viktor 1000 points fitted rational. The rational will run on Excel, no sweat !
Jean
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
On 9/11/2009 5:44:17 PM, ArtZ wrote:
>Jean,
>
>This gets circular doesn't it.
>It definitely appears that
>there's not a simple
>approximation of Viktor's diff
>eq solution.
>
>What Viktor's solution does
>tell me (I think) is that some
>form of Verhulst is the
>answer.
>
>I don't see a way to directly
>integrate Viktor's diff eq, do
>you?
>
>You rational fraction scare
>me!
>
>Art
______________________________
Circular: yes, because fitting Viktor is apparently fitting the original data. That there is another form of Verhulst, maybe. "Integrate Viktor" you mean solve the DE ? Don't be scared by rational fractions, all (if not) computer approximations run rational fractions !
Jean
>Jean,
>
>This gets circular doesn't it.
>It definitely appears that
>there's not a simple
>approximation of Viktor's diff
>eq solution.
>
>What Viktor's solution does
>tell me (I think) is that some
>form of Verhulst is the
>answer.
>
>I don't see a way to directly
>integrate Viktor's diff eq, do
>you?
>
>You rational fraction scare
>me!
>
>Art
______________________________
Circular: yes, because fitting Viktor is apparently fitting the original data. That there is another form of Verhulst, maybe. "Integrate Viktor" you mean solve the DE ? Don't be scared by rational fractions, all (if not) computer approximations run rational fractions !
Jean
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
>>Yes, I would like to be able to extrapolate for both time and temperature to compare with actual data with different times and temperatures. <<br> ___________________
You mean ! interpolate !
You can with Viktor DE. You can wth L(,,,,,x).
Below big Marlett 20, here is JG(k,xo,n,x). This fit is damned good too. You can slide and whereas it is a function, you can "interpolate". This last fit, toke at least 3 hrs to initialise, read well: initialise. Just enough to make me laugh when I read about automating the fitting session. The generalised 5/5 rational, you can slide too (left slided).
Jean
You mean ! interpolate !
You can with Viktor DE. You can wth L(,,,,,x).
Below big Marlett 20, here is JG(k,xo,n,x). This fit is damned good too. You can slide and whereas it is a function, you can "interpolate". This last fit, toke at least 3 hrs to initialise, read well: initialise. Just enough to make me laugh when I read about automating the fitting session. The generalised 5/5 rational, you can slide too (left slided).
Jean
Sep 12, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 12, 2009
03:00 AM
On 9/11/2009 1:42:29 PM, ArtZ wrote:
>In regards to Richard's
>comments. Yes, I would like to
>be able to extrapolate for
>both time and temperature to
>compare with actual data with
>different times and
>temperatures.
In which case you should really be fitting a surface to all the data at once: both time and temperature axes.
>n*/n = A*exp(-(E/RT))
Yes, I am familiar with the Arrhenius equation
>Richard, sorry for the long
>answer, but yes, until the
>reactants exceed the energy
>barrier, cell death is not
>probable.
I was referring to the behavior on the time axis though, not the temperature axis (which you didn't even post data for), so the temperature is constant, and the probability of exceeding the activation energy is therefore constant. It just seemed odd to me that the cell population had zero deaths for quite some time, then all of a sudden they start dropping like flies. It's way outside my field though, so maybe that's just the way cells behave.
Richard
>In regards to Richard's
>comments. Yes, I would like to
>be able to extrapolate for
>both time and temperature to
>compare with actual data with
>different times and
>temperatures.
In which case you should really be fitting a surface to all the data at once: both time and temperature axes.
>n*/n = A*exp(-(E/RT))
Yes, I am familiar with the Arrhenius equation
>Richard, sorry for the long
>answer, but yes, until the
>reactants exceed the energy
>barrier, cell death is not
>probable.
I was referring to the behavior on the time axis though, not the temperature axis (which you didn't even post data for), so the temperature is constant, and the probability of exceeding the activation energy is therefore constant. It just seemed odd to me that the cell population had zero deaths for quite some time, then all of a sudden they start dropping like flies. It's way outside my field though, so maybe that's just the way cells behave.
Richard
Sep 14, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 14, 2009
03:00 AM
All,
Thanks for all the effort. It seems that Viktor's DE is closest to the mark based on the Arrhenius relationship.
My data was for a single temperature (isothermal bath. Using Viktor's DE where y(t) is the linear term (time) and z(t) the exponential (temperature), it fits well with the exponential nature of the Arrhenius relationship.
Is there a way determine y(t) and z(t)? I think that's the way to go. But, as Jean points out, those functions could be complicated as well.
Spline interpolation smooths the data nicely as shown in the attached worksheet. I used a VBA macro to do this in Excel.
Sure, it goes through all the points and the residual are zero, but it doesn't allow extrapolation.
BTW, Jean, I am using MC13. 🙂
Art
Thanks for all the effort. It seems that Viktor's DE is closest to the mark based on the Arrhenius relationship.
My data was for a single temperature (isothermal bath. Using Viktor's DE where y(t) is the linear term (time) and z(t) the exponential (temperature), it fits well with the exponential nature of the Arrhenius relationship.
Is there a way determine y(t) and z(t)? I think that's the way to go. But, as Jean points out, those functions could be complicated as well.
Spline interpolation smooths the data nicely as shown in the attached worksheet. I used a VBA macro to do this in Excel.
Sure, it goes through all the points and the residual are zero, but it doesn't allow extrapolation.
BTW, Jean, I am using MC13. 🙂
Art
Sep 14, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 14, 2009
03:00 AM
What are you trying to accomplish with what you call the spline interpolation?
Interpolation, spline or otherwise, is not smoothing. By definition it goes through all the data points. Signal or noise, it does not care, it fits it all.
And why Excel? Mathcad has a number of cubic spline implementations avaiable, no VB code needed.
But the only purpose of an interpolation is to provide some sort of values for intermediate points. The question is, why do you want such values? What are you going to do with them? They carry no independent information, and are not needed, nor useful, for model building or curve fitting.
__________________
� � � � Tom Gutman
Interpolation, spline or otherwise, is not smoothing. By definition it goes through all the data points. Signal or noise, it does not care, it fits it all.
And why Excel? Mathcad has a number of cubic spline implementations avaiable, no VB code needed.
But the only purpose of an interpolation is to provide some sort of values for intermediate points. The question is, why do you want such values? What are you going to do with them? They carry no independent information, and are not needed, nor useful, for model building or curve fitting.
__________________
� � � � Tom Gutman
Sep 14, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 14, 2009
03:00 AM
Tom,
I didn't plan to use the interpolation - as you suggest, there is no new information.
It seemed that Jean and Theodore were promoting interpolation.
In my world, I need to use XL when I can in order to share more easily with colleagues - most use XL readily and Mathcad hardly at all.
I still think that I would have what I want if I could derive analytical functions for y(t) and z(t) in Viktor's DE.
What do you think?
Art
I didn't plan to use the interpolation - as you suggest, there is no new information.
It seemed that Jean and Theodore were promoting interpolation.
In my world, I need to use XL when I can in order to share more easily with colleagues - most use XL readily and Mathcad hardly at all.
I still think that I would have what I want if I could derive analytical functions for y(t) and z(t) in Viktor's DE.
What do you think?
Art


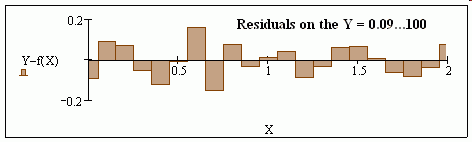{kind=link}
{kind=link}