
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Community Tip - Want the oppurtunity to discuss enhancements to PTC products? Join a working group! X
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Vector and Range Variable
Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 18, 2009
03:00 AM
Vector and Range Variable

Labels:
- Labels:
-
Physics
40 REPLIES 40
Aug 18, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Aug 18, 2009
03:00 AM
Wow - that is nasty.
It has always been difficult to explain the difference between a range variable and a vector.
I see that somebody needed to have that talk with the new software engineers.
Good catch,
- Guy
It has always been difficult to explain the difference between a range variable and a vector.
I see that somebody needed to have that talk with the new software engineers.
Good catch,
- Guy
Sep 09, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 09, 2009
03:00 AM
I logged this.
Mona
Mona
Sep 09, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 09, 2009
03:00 AM
I think that if you want to treat a range variable as a vector (with subscripting capability) then it should be a true vector, transposable and all the rest. If it's not a vector, then you shouldn't be able to address it by subscripting. This is simply adding to the confusion. . .
Fred Kohlhepp
fkohlhepp@sikorsky.com
Fred Kohlhepp
fkohlhepp@sikorsky.com
Sep 09, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 09, 2009
03:00 AM
On 9/9/2009 12:39:48 PM, fkohlhepp wrote:
>I think that if you want to
>treat a range variable as a
>vector (with subscripting
>capability) then it should be
>a true vector, transposable
>and all the rest. If it's not
>a vector, then you shouldn't
>be able to address it by
>subscripting. This is simply
>adding to the confusion. . .
I agree. I also think that making them display in an identical way when they are evaluated is just asking for trouble. You can examine two variable to see what they are, and the look identical. Then they behave differently when you try to use them.
Indexing of range variables should not be allowed at all, and if it is allowed you should not be able to index out of range.
Richard
>I think that if you want to
>treat a range variable as a
>vector (with subscripting
>capability) then it should be
>a true vector, transposable
>and all the rest. If it's not
>a vector, then you shouldn't
>be able to address it by
>subscripting. This is simply
>adding to the confusion. . .
I agree. I also think that making them display in an identical way when they are evaluated is just asking for trouble. You can examine two variable to see what they are, and the look identical. Then they behave differently when you try to use them.
Indexing of range variables should not be allowed at all, and if it is allowed you should not be able to index out of range.
Richard
Sep 09, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 09, 2009
03:00 AM
I agree with both of you.
Thanks,
Mona
Thanks,
Mona
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
Aside:
I think vectors which represent the uniform sampling of something along a real world measurement axis (e.g. every 0.1s, or every 2.7kg) should be indexable using that unit of measurement (cardinality to within TOL), so that the sample value at 0.3s or sample value at 10.8kg could be accessed. That indexing should be possible using range variables as well.
Doen't quite answer the "is a range variable also a vector question"
Philip Oakley
I think vectors which represent the uniform sampling of something along a real world measurement axis (e.g. every 0.1s, or every 2.7kg) should be indexable using that unit of measurement (cardinality to within TOL), so that the sample value at 0.3s or sample value at 10.8kg could be accessed. That indexing should be possible using range variables as well.
Doen't quite answer the "is a range variable also a vector question"
Philip Oakley
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 11:20:18 AM, philipoakley wrote:
>Aside:
>I think vectors which
>represent the uniform sampling
>of something along a real
>world measurement axis (e.g.
>every 0.1s, or every 2.7kg)
>should be indexable using that
>unit of measurement
>(cardinality to within TOL),
>so that the sample value at
>0.3s or sample value at 10.8kg
>could be accessed.
What's wrong with "match"?
> That
>indexing should be possible
>using range variables as well.
I disagree. Range variables are not vectors: they consist of a start, an increment, and a (nominal) end. Indexing that is not possible. When you talk about indexing a range variable you are mentally using the range definition to create a vector, and then indexing the vector. If that's what you want, then you should be using vectors in the first place.
Richard
>Aside:
>I think vectors which
>represent the uniform sampling
>of something along a real
>world measurement axis (e.g.
>every 0.1s, or every 2.7kg)
>should be indexable using that
>unit of measurement
>(cardinality to within TOL),
>so that the sample value at
>0.3s or sample value at 10.8kg
>could be accessed.
What's wrong with "match"?
> That
>indexing should be possible
>using range variables as well.
I disagree. Range variables are not vectors: they consist of a start, an increment, and a (nominal) end. Indexing that is not possible. When you talk about indexing a range variable you are mentally using the range definition to create a vector, and then indexing the vector. If that's what you want, then you should be using vectors in the first place.
Richard
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
>Range variables are not vectors.
I think a range variable is (must be) one special form of a vectors.
We can have possibility to input in sheet:
v:=stack(1, 1.5, 2, 2.5, 3)
v[1=1.5
or
v:=1, 1.5 .. 3
Val
http://twt.mpei.ac.ru/ochkov/v_ochkov.htm
I think a range variable is (must be) one special form of a vectors.
We can have possibility to input in sheet:
v:=stack(1, 1.5, 2, 2.5, 3)
v[1=1.5
or
v:=1, 1.5 .. 3
Val
http://twt.mpei.ac.ru/ochkov/v_ochkov.htm
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 12:28:04 PM, VFO wrote:
>>Range variables are not vectors.
>I think a range variable is
>(must be) one special form of
>a vectors.
>We can have possibility to
>input in sheet:
>v:=stack(1, 1.5, 2, 2.5, 3)
>v[1=1.5
>or
>v:=1, 1.5 .. 3
Are you arguing for what you want it to be, or what it currently is? Currently, it is not any sort of vector. Given an option of what I would like it to be, I would get rid of range variables altogether. A range definition would just create a vector, and anything that currently uses a range variable would use a vector instead.
Richard
>>Range variables are not vectors.
>I think a range variable is
>(must be) one special form of
>a vectors.
>We can have possibility to
>input in sheet:
>v:=stack(1, 1.5, 2, 2.5, 3)
>v[1=1.5
>or
>v:=1, 1.5 .. 3
Are you arguing for what you want it to be, or what it currently is? Currently, it is not any sort of vector. Given an option of what I would like it to be, I would get rid of range variables altogether. A range definition would just create a vector, and anything that currently uses a range variable would use a vector instead.
Richard
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
On 9/10/2009 12:50:04 PM, rijackson wrote:
>Given an
>option of what I would like it to be, I
>would get rid of range variables
>altogether. A range definition would
>just create a vector, and anything that
>currently uses a range variable would
>use a vector instead.
Without range variables as indexes, the old iteraative solution technique:
x[i:C*x[(i-1)
would be lost.
Fred Kohlhepp
fkohlhepp@sikorsky.com
>Given an
>option of what I would like it to be, I
>would get rid of range variables
>altogether. A range definition would
>just create a vector, and anything that
>currently uses a range variable would
>use a vector instead.
Without range variables as indexes, the old iteraative solution technique:
x[i:C*x[(i-1)
would be lost.
Fred Kohlhepp
fkohlhepp@sikorsky.com
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
On 9/11/2009 6:16:29 AM, fkohlhepp wrote:
>Without range variables as indexes, the
>old iteraative solution technique:
>
>x[i:C*x[(i-1)
>
>would be lost.
Yes, that's true. I don't see a way to do that if i was a vector.
Richard
>Without range variables as indexes, the
>old iteraative solution technique:
>
>x[i:C*x[(i-1)
>
>would be lost.
Yes, that's true. I don't see a way to do that if i was a vector.
Richard
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
On 9/11/2009 6:16:29 AM, fkohlhepp wrote:
== Without range variables as indexes, the old iteraative solution technique:
== x[i:C*x[(i-1)
== would be lost.
Yes. That's nagging at me as well.
One of the concepts being talked about seems to take range specifications as a means of indexing over several elements at once. However, there is an ambiguity as to whether
xi+1:=C·xi means
a. Calculate C times the subvector of x whose indices are the elements of i. Assign the resulting data structure (say a vector) to those elements of x whose indices are the elements of i plus 1.
b. Iterate over the expression, using each element of i in turn as an index.
These are fundamentally different; the former is parallel whilst the latter is sequential.
So, taking Richard's example, what would A1..4,4..12 := 0.5·(A0..3,3..11+N/A0..3,3..11) actually mean?
In addition, whilst I'm happy conceptually to allow out-of-bounds 'indexing' of range variables, I don't think that should be allowed with vectors as vectors are a specific set of values rather than a specification for those values.
I remain optimistic that the confusion between range variables and vectors is addressable if the concepts are introduced properly.
Stuart
== Without range variables as indexes, the old iteraative solution technique:
== x[i:C*x[(i-1)
== would be lost.
Yes. That's nagging at me as well.
One of the concepts being talked about seems to take range specifications as a means of indexing over several elements at once. However, there is an ambiguity as to whether
xi+1:=C·xi means
a. Calculate C times the subvector of x whose indices are the elements of i. Assign the resulting data structure (say a vector) to those elements of x whose indices are the elements of i plus 1.
b. Iterate over the expression, using each element of i in turn as an index.
These are fundamentally different; the former is parallel whilst the latter is sequential.
So, taking Richard's example, what would A1..4,4..12 := 0.5·(A0..3,3..11+N/A0..3,3..11) actually mean?
In addition, whilst I'm happy conceptually to allow out-of-bounds 'indexing' of range variables, I don't think that should be allowed with vectors as vectors are a specific set of values rather than a specification for those values.
I remain optimistic that the confusion between range variables and vectors is addressable if the concepts are introduced properly.
Stuart
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
On 9/11/2009 8:22:01 AM, stuartafbruff wrote:
>So, taking Richard's example, what would
>A1..4,4..12 :=
>0.5�(A0..3,3..11+N/A0..3,3..11)
>actually mean?
The same as it does now
I had contemplated it only as a substitute for submatrix, so if there is no range indexing on the lhs, I think it's clear what this
X:A[1..4,4..12
should do, but it doesn't work.
>In addition, whilst I'm happy
>conceptually to allow out-of-bounds
>'indexing' of range variables, I don't
>think that should be allowed with
>vectors as vectors are a specific set of
>values rather than a specification for
>those values.
I would certainly agree with that!
Richard
>So, taking Richard's example, what would
>A1..4,4..12 :=
>0.5�(A0..3,3..11+N/A0..3,3..11)
>actually mean?
The same as it does now
I had contemplated it only as a substitute for submatrix, so if there is no range indexing on the lhs, I think it's clear what this
X:A[1..4,4..12
should do, but it doesn't work.
>In addition, whilst I'm happy
>conceptually to allow out-of-bounds
>'indexing' of range variables, I don't
>think that should be allowed with
>vectors as vectors are a specific set of
>values rather than a specification for
>those values.
I would certainly agree with that!
Richard
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
I should have added that it's also not logical that this does not work:

Perhaps this discussion is kind of pointless right now though. The first step (which is possibly going to be a great many steps, some of which may never happen) is just to get back to where we were.
Richard
Perhaps this discussion is kind of pointless right now though. The first step (which is possibly going to be a great many steps, some of which may never happen) is just to get back to where we were.
Richard
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
>>Without range variables as indexes, the old iteraative solution technique:
x[i:C*x[(i-1)
would be lost. <<
Why? Why should a vector i not do as well? The presence of a vector as a subscript on the left of an assignment can be used to implicitly define a loop through the values of the vector, just as the presence of a range variable in that context currently implies a loop through the values of the range variable.
Subscripting by other than integers is a completely different problem. Indexing is essentially a form of function evaluation. It works easily in Mathcad because Mathcad vectors are, mathematically speaking, sequences, mappings of an integer into some range. This is a standard and well defined concept, and so can be used directly. To extend it to a different domain requires a full specification of the mapping. That is not so standard, there are many different, equally useful (in different contexts) concepts available. Standard functions based on algebraic expressions, interpolations of various sorts, table lookups of various sorts, all have their uses. And costs.
The most general solution would be some sort of associative memory, like Visual Basic's dictionaly object. This would be a useful addition to Mathcad's arsenal. But it is a fairly high overhead process, and not really suitable as a replacement for simple indexing. Nor is it capable or functionally replacing interpolations, like the cubic splines.
__________________
� � � � Tom Gutman
x[i:C*x[(i-1)
would be lost. <<
Why? Why should a vector i not do as well? The presence of a vector as a subscript on the left of an assignment can be used to implicitly define a loop through the values of the vector, just as the presence of a range variable in that context currently implies a loop through the values of the range variable.
Subscripting by other than integers is a completely different problem. Indexing is essentially a form of function evaluation. It works easily in Mathcad because Mathcad vectors are, mathematically speaking, sequences, mappings of an integer into some range. This is a standard and well defined concept, and so can be used directly. To extend it to a different domain requires a full specification of the mapping. That is not so standard, there are many different, equally useful (in different contexts) concepts available. Standard functions based on algebraic expressions, interpolations of various sorts, table lookups of various sorts, all have their uses. And costs.
The most general solution would be some sort of associative memory, like Visual Basic's dictionaly object. This would be a useful addition to Mathcad's arsenal. But it is a fairly high overhead process, and not really suitable as a replacement for simple indexing. Nor is it capable or functionally replacing interpolations, like the cubic splines.
__________________
� � � � Tom Gutman
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
One of the problems with using a vector to replace a range variable for indexing operations is that it has to be defined, and take up memory, before it can be used. I stared at Python a year or so ago, and it appeared to me that it ran very slowly because it was building vectors before using them to access array elements. I'm not entirely sure on this as it might have been building iterators - something that may as well pop up in this thread - rather than using a simple index to compute array offsets. I don't see a good intro on iterators, but here's one of the more popular google links on the subject http://www.boost.org/doc/libs/1_38_0/libs/numeric/ublas/doc/iterator_concept.htm
As Tom points out, indexing with other than integers opens a whole new topic in itself. Iterators are one of the common ways of stepping through things like maps and sparse arrays, but they can be very confusing for some people. The attached file shows an iterator-like definition of a vector summation rather than using an index variable.
Robert
As Tom points out, indexing with other than integers opens a whole new topic in itself. Iterators are one of the common ways of stepping through things like maps and sparse arrays, but they can be very confusing for some people. The attached file shows an iterator-like definition of a vector summation rather than using an index variable.
Robert
Sep 11, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 11, 2009
03:00 AM
We're back to implementation issues. There does not have to be a single internal representation of vectors. Once can easily have multiple internal forms for vectors, as long as they behave, externally, the same. In particular, there is no reason why Mathcad cannot store APVs (arithmetic progression vectors) in a compact form, using only three parameters. Operators can be written to use the compact representation directly, where that is possible, with the general fall back procedure of expanding the vector into an elemental form when necessary.
__________________
� � � � Tom Gutman
__________________
� � � � Tom Gutman
Sep 13, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 13, 2009
03:00 AM
On 9/11/2009 5:50:36 PM, Tom_Gutman wrote:
>> Without range variables as indexes, the old
iteraative solution technique:
>> x[i:C*x[(i-1)
>> would be lost.
== Why? Why should a vector i not do as well? The
presence of a vector as a subscript on the left of
an assignment can be used to implicitly define a
loop through the values of the vector, just as the
presence of a range variable in that context
currently implies a loop through the values of the
range variable.
A vector wouldn't do as well as a range variable
for several reasons.
1. see my message dated 9/11/2009 8:22:01 AM: because there are two distinct meanings to
xk:= 3 · xk-1;
(a). Carry out the multiplication on the subvector
of x given by the indices contained in (k-1) and
then put the result in the indices contained in
(k).
(b). Iterate over k ... (as per range variable).
Clearly the results are different and so one form
must be selected as "The Interpretation". As
several of the "indexing" complaints about
confusing range variables and vectors come from
users of other packages, such as Matlab, it's
worth looking at what they do. The ones I've
looked at (Matlab, FORTRAN 90(+), J, Maple,
Mathematica) seem to consistently take view (a),
and the examples of recurrence relations I've
found in Matlab, FORTRAN and J use loops to handle
recurrence (Mathematica and Maple use an explicit
solver 'rsolve'). Consequently, it would make
sense to go with this intepretation as it offers a
more direct route into Mathcad. As even Spirit
will eventually include for / while loops, there
is no necessity for range variables but there is a
need to set (arbitrary) elements of arrays.
2. The second reason is that a vector (array) is
just a collection of values. By changing it's
behaviour dependent upon context, there is a
danger that (significant) mistakes will be made
and not easily picked up by a reviewer. The
presence of a specific iterator (the range
variable) does away with the problem of changes in
array behaviour occuring, and although it
introduces its own interpretational problems, at
least a reviewer has a fighting chance of noting
that 'k' is a range variable and not a vector.
Applying a style to distinguish between the two
types could also aid matters and, after being
bitten a couple of times, most people seem to be
able to cope with the difference.
3. Not only is a vector just a collection of
values, it is specifically defined to be a bounded
collection - you can't read an element that
doesn't exist. However, as Valery's "Feature"
shows, the same is not necessarily true of a range
definition. It is potentially very useful to be
able to calculate an arbitrary member of a
sequence. Strictly, all that would be necessary
is to give the 1st, 2nd and 3rd members of the
series, but specifying an end value allows the
user (as at present) to specify a default set of
iteration values (as previously mentioned, I'd
like to see the concept of range definitions
(a,b..c) generalized to include strings and higher
order / arbitrary sequences and even be allowed
within programs).
At the moment, I'm in favour of retaining range
variables and keeping this delightful new feature
that Val discovered ...
Stuart
>> Without range variables as indexes, the old
iteraative solution technique:
>> x[i:C*x[(i-1)
>> would be lost.
== Why? Why should a vector i not do as well? The
presence of a vector as a subscript on the left of
an assignment can be used to implicitly define a
loop through the values of the vector, just as the
presence of a range variable in that context
currently implies a loop through the values of the
range variable.
A vector wouldn't do as well as a range variable
for several reasons.
1. see my message dated 9/11/2009 8:22:01 AM: because there are two distinct meanings to
xk:= 3 · xk-1;
(a). Carry out the multiplication on the subvector
of x given by the indices contained in (k-1) and
then put the result in the indices contained in
(k).
(b). Iterate over k ... (as per range variable).
Clearly the results are different and so one form
must be selected as "The Interpretation". As
several of the "indexing" complaints about
confusing range variables and vectors come from
users of other packages, such as Matlab, it's
worth looking at what they do. The ones I've
looked at (Matlab, FORTRAN 90(+), J, Maple,
Mathematica) seem to consistently take view (a),
and the examples of recurrence relations I've
found in Matlab, FORTRAN and J use loops to handle
recurrence (Mathematica and Maple use an explicit
solver 'rsolve'). Consequently, it would make
sense to go with this intepretation as it offers a
more direct route into Mathcad. As even Spirit
will eventually include for / while loops, there
is no necessity for range variables but there is a
need to set (arbitrary) elements of arrays.
2. The second reason is that a vector (array) is
just a collection of values. By changing it's
behaviour dependent upon context, there is a
danger that (significant) mistakes will be made
and not easily picked up by a reviewer. The
presence of a specific iterator (the range
variable) does away with the problem of changes in
array behaviour occuring, and although it
introduces its own interpretational problems, at
least a reviewer has a fighting chance of noting
that 'k' is a range variable and not a vector.
Applying a style to distinguish between the two
types could also aid matters and, after being
bitten a couple of times, most people seem to be
able to cope with the difference.
3. Not only is a vector just a collection of
values, it is specifically defined to be a bounded
collection - you can't read an element that
doesn't exist. However, as Valery's "Feature"
shows, the same is not necessarily true of a range
definition. It is potentially very useful to be
able to calculate an arbitrary member of a
sequence. Strictly, all that would be necessary
is to give the 1st, 2nd and 3rd members of the
series, but specifying an end value allows the
user (as at present) to specify a default set of
iteration values (as previously mentioned, I'd
like to see the concept of range definitions
(a,b..c) generalized to include strings and higher
order / arbitrary sequences and even be allowed
within programs).
At the moment, I'm in favour of retaining range
variables and keeping this delightful new feature
that Val discovered ...
Stuart
Sep 14, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 14, 2009
03:00 AM
On 9/14/2009 7:59:22 AM, fkohlhepp wrote:
>On 9/11/2009 5:50:36 PM, Tom_Gutman
>wrote:
>>>>Without range variables as indexes, the old iteraative solution technique:
>>
>>x[i:C*x[(i-1)
>>
>>would be lost. <<
>>
>>Why? Why should a vector i
>>not do as well?
Maybe I'm missing a point; how do you use a vector to address one element in a vector?
>Fred Kohlhepp
>fkohlhepp@sikorsky.com
Fred Kohlhepp
fkohlhepp@sikorsky.com
>On 9/11/2009 5:50:36 PM, Tom_Gutman
>wrote:
>>>>Without range variables as indexes, the old iteraative solution technique:
>>
>>x[i:C*x[(i-1)
>>
>>would be lost. <<
>>
>>Why? Why should a vector i
>>not do as well?
Maybe I'm missing a point; how do you use a vector to address one element in a vector?
>Fred Kohlhepp
>fkohlhepp@sikorsky.com
Fred Kohlhepp
fkohlhepp@sikorsky.com
Sep 14, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 14, 2009
03:00 AM
On 9/14/2009 8:00:57 AM, fkohlhepp wrote:
== Maybe I'm missing a point; how do you use a vector to address one element in a vector?
Use a single element vector. The indicial engine looks at index variable, sees it's a vector and then looks inside to see what actual indices it contains. For example,
j:=9
xj
and
v:=[9]
xv
would be equivalent.
However, my greater objection to using vectors to act as context-dependent iterators (ie, like range variables) is given in my previous message.
Stuart
== Maybe I'm missing a point; how do you use a vector to address one element in a vector?
Use a single element vector. The indicial engine looks at index variable, sees it's a vector and then looks inside to see what actual indices it contains. For example,
j:=9
xj
and
v:=[9]
xv
would be equivalent.
However, my greater objection to using vectors to act as context-dependent iterators (ie, like range variables) is given in my previous message.
Stuart
Sep 14, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 14, 2009
03:00 AM
On 9/14/2009 8:05:26 AM, stuartafbruff wrote:
>On 9/14/2009 8:00:57 AM, fkohlhepp
>wrote:
>== Maybe I'm missing a point; how do you
>use a vector to address one element in a
>vector?
>
>Use a single element vector. The
>indicial engine looks at index variable,
>sees it's a vector and then looks inside
>to see what actual indices it contains.
>For example,
>
>j:=9
>xj
>
>and
>
>v:=[9]
>xv
>
>would be equivalent.
>
>However, my greater objection to using
>vectors to act as context-dependent
>iterators (ie, like range variables) is
>given in my previous message.
>
>Stuart
That message was useful and illuminating.
For my suggestion I was using the presence of a Unit[dimension] as the discriminator as to indexing type, but it did not address your sub-matrix condition, which I hadn't (at that time) understood.
There is, as you say, differnce between iteration and sub-matrix actions that is not easy to resolve!
Philip Oakley
>On 9/14/2009 8:00:57 AM, fkohlhepp
>wrote:
>== Maybe I'm missing a point; how do you
>use a vector to address one element in a
>vector?
>
>Use a single element vector. The
>indicial engine looks at index variable,
>sees it's a vector and then looks inside
>to see what actual indices it contains.
>For example,
>
>j:=9
>xj
>
>and
>
>v:=[9]
>xv
>
>would be equivalent.
>
>However, my greater objection to using
>vectors to act as context-dependent
>iterators (ie, like range variables) is
>given in my previous message.
>
>Stuart
That message was useful and illuminating.
For my suggestion I was using the presence of a Unit[dimension] as the discriminator as to indexing type, but it did not address your sub-matrix condition, which I hadn't (at that time) understood.
There is, as you say, differnce between iteration and sub-matrix actions that is not easy to resolve!
Philip Oakley
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 12:28:04 PM, VFO wrote:
I think a range variable is (must be) one special form of a vectors.
We can have possibility to input in sheet:
v:=stack(1, 1.5, 2, 2.5, 3)
v[1=1.5
or
v:=1, 1.5 .. 3
I think the distinction is important (at the moment).
One advantage of a range variable is that it consumes minimal memory, whereas a vector would consumes as much memory as is needed to hold the corresponding number of values.
One thing I would like to see is the concept of the range specification generalized to other data types and more complex sequences (eg strings and quadratics - see http://collab.mathsoft.com/read?114862,12 )
I'd also like to consider extending the concept of 'sequences' (see below) into the common usage. Sequences are currently only used in program for loops, but it would be nice to see them introduced as a formal data type that could be assigned to a variable (ie, extending the concept of a 'range variable' to become a 'sequence variable')
I'd also like to be a little bit heretical and suggest that the 'bug' you reported above may be worth looking at as a 'feature' instead 🙂 Try
a:=1.0, 1.2 .. 2.0
k:=0..30
b[k:=a[k
j:=0..10
c[j:=a[j
This allows the generation of several vectors with the same increments but different lengths from a single specification. Yes, it will undoubtedly confuse many people, but given that range variables v vectors cause confusion anyway perhaps the extra utility will make the 'learning curve' confusion worthwhile.
Stuart
Looking at what we have in M14, then:
A range specification is a data type that takes the form 'start_value, next_value .. last_value' or 'start_value .. last_value', where start_value is a real number and ',' and '..' are part of the specification. If next_value is omitted then a value of start_value+1 is assumed.
A range specification is shorthand for a linear sequence of values lying between start_value and last_value in increments of next_value-start_value.
A variable that holds a range specification is referred to as a 'range variable'.
A sequence is a data type that takes the form 'value_0, value_1{,value_2 ... }', where value_n is of any data type (including a range specification) and ',' is part of the specification. '{','}' and '...' indicate that the sequence may optionally have more than two values. Note that where a value is a full form range specification, then it must be enclosed in parentheses (eg, '1,5, (0.1,0.2..0.9), 7')
I think a range variable is (must be) one special form of a vectors.
We can have possibility to input in sheet:
v:=stack(1, 1.5, 2, 2.5, 3)
v[1=1.5
or
v:=1, 1.5 .. 3
I think the distinction is important (at the moment).
One advantage of a range variable is that it consumes minimal memory, whereas a vector would consumes as much memory as is needed to hold the corresponding number of values.
One thing I would like to see is the concept of the range specification generalized to other data types and more complex sequences (eg strings and quadratics - see http://collab.mathsoft.com/read?114862,12 )
I'd also like to consider extending the concept of 'sequences' (see below) into the common usage. Sequences are currently only used in program for loops, but it would be nice to see them introduced as a formal data type that could be assigned to a variable (ie, extending the concept of a 'range variable' to become a 'sequence variable')
I'd also like to be a little bit heretical and suggest that the 'bug' you reported above may be worth looking at as a 'feature' instead 🙂 Try
a:=1.0, 1.2 .. 2.0
k:=0..30
b[k:=a[k
j:=0..10
c[j:=a[j
This allows the generation of several vectors with the same increments but different lengths from a single specification. Yes, it will undoubtedly confuse many people, but given that range variables v vectors cause confusion anyway perhaps the extra utility will make the 'learning curve' confusion worthwhile.
Stuart
Looking at what we have in M14, then:
A range specification is a data type that takes the form 'start_value, next_value .. last_value' or 'start_value .. last_value', where start_value is a real number and ',' and '..' are part of the specification. If next_value is omitted then a value of start_value+1 is assumed.
A range specification is shorthand for a linear sequence of values lying between start_value and last_value in increments of next_value-start_value.
A variable that holds a range specification is referred to as a 'range variable'.
A sequence is a data type that takes the form 'value_0, value_1{,value_2 ... }', where value_n is of any data type (including a range specification) and ',' is part of the specification. '{','}' and '...' indicate that the sequence may optionally have more than two values. Note that where a value is a full form range specification, then it must be enclosed in parentheses (eg, '1,5, (0.1,0.2..0.9), 7')
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
The memory issue is irrelevant. That is just a matter of how the implementation chooses to store values. There is no law that says that all vectors must be internally represented the same way. That is already the case in MC14, where a vector that is the result of a column select operator is internally represented by quite a different structure from one that has bee constructed with an array constructor.
I would like to see no distinction between a range value and a vector (at the user level), the range value notation becomes just a short form for specifying vectors with certain properties. Internally Mathcad may choose to represent APVs (arithmetic progression vectors) with three values (suitably chosen from among start value, increment, second value, end value, number of elements). It may also choose to implement special forms (internally, of course) for some operations, like adding a scalar to a vector or multiplying a vector by a scalar, that make APVs out of APVs.
Failing a complete logical identity, I see any commonality as good, a step along the path to what is desired. I have no problem with subscripting range variables (although there is a question as to whether such subscripting should be allowed to extrapolate). An obvious next step would be the ability to use submatrix on a range variable. Then, of course, length and last. There are times when salami tactics work.
__________________
� � � � Tom Gutman
I would like to see no distinction between a range value and a vector (at the user level), the range value notation becomes just a short form for specifying vectors with certain properties. Internally Mathcad may choose to represent APVs (arithmetic progression vectors) with three values (suitably chosen from among start value, increment, second value, end value, number of elements). It may also choose to implement special forms (internally, of course) for some operations, like adding a scalar to a vector or multiplying a vector by a scalar, that make APVs out of APVs.
Failing a complete logical identity, I see any commonality as good, a step along the path to what is desired. I have no problem with subscripting range variables (although there is a question as to whether such subscripting should be allowed to extrapolate). An obvious next step would be the ability to use submatrix on a range variable. Then, of course, length and last. There are times when salami tactics work.
__________________
� � � � Tom Gutman
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 2:15:27 PM, Tom_Gutman wrote:
>The memory issue is
>irrelevant. That is just a
>matter of how the
>implementation chooses to
>store values. There is no law
>that says that all vectors
>must be internally represented
>the same way. That is already
>the case in MC14, where a
>vector that is the result of a
>column select operator is
>internally represented by
>quite a different structure
>from one that has bee
>constructed with an array
>constructor.
>
>I would like to see no
>distinction between a range
>value and a vector (at the
>user level), the range value
>notation becomes just a short
>form for specifying vectors
>with certain properties.
>Internally Mathcad may choose
>to represent APVs (arithmetic
>progression vectors) with
>three values (suitably chosen
>from among start value,
>increment, second value, end
>value, number of elements).
>It may also choose to
>implement special forms
>(internally, of course) for
>some operations, like adding a
>scalar to a vector or
>multiplying a vector by a
>scalar, that make APVs out of
>APVs.
I agree with all of that.
>Failing a complete logical
>identity, I see any
>commonality as good, a step
>along the path to what is
>desired.
There I disagree. If they are obviously distinct there would be no confusion. If they were the same thing there would be no confusion (obviously). If they are similar but distinct though, then that does lead confusion. If you make them almost the same, so that they even look identical when evaluated and can be indexed the same way, but they are not the same and behave differently in certain cases, then users are going to be really confused. There would need to be some significant benefit to justify that. More significant than any benefit I can think of.
Richard
>The memory issue is
>irrelevant. That is just a
>matter of how the
>implementation chooses to
>store values. There is no law
>that says that all vectors
>must be internally represented
>the same way. That is already
>the case in MC14, where a
>vector that is the result of a
>column select operator is
>internally represented by
>quite a different structure
>from one that has bee
>constructed with an array
>constructor.
>
>I would like to see no
>distinction between a range
>value and a vector (at the
>user level), the range value
>notation becomes just a short
>form for specifying vectors
>with certain properties.
>Internally Mathcad may choose
>to represent APVs (arithmetic
>progression vectors) with
>three values (suitably chosen
>from among start value,
>increment, second value, end
>value, number of elements).
>It may also choose to
>implement special forms
>(internally, of course) for
>some operations, like adding a
>scalar to a vector or
>multiplying a vector by a
>scalar, that make APVs out of
>APVs.
I agree with all of that.
>Failing a complete logical
>identity, I see any
>commonality as good, a step
>along the path to what is
>desired.
There I disagree. If they are obviously distinct there would be no confusion. If they were the same thing there would be no confusion (obviously). If they are similar but distinct though, then that does lead confusion. If you make them almost the same, so that they even look identical when evaluated and can be indexed the same way, but they are not the same and behave differently in certain cases, then users are going to be really confused. There would need to be some significant benefit to justify that. More significant than any benefit I can think of.
Richard
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
>>If they are obviously distinct there would be no confusion. If they were the same thing there would be no confusion (obviously). If they are similar but distinct though, then that does lead confusion.<<
Here we're just going to disagree. Confusion already abounds, allowing subscripts on range variables is not going to increase confusion.
The real problem is that vectors and range variables are conceptually the same, regardless of whatever implementation difference are implemented. They both represent sequences of values. That is the user's viewpoint, and it's not going to change. The choices are to try to train users to recognize the implementation differences and restrictions, or to do an implementation that matches the usual concept. I go for the latter, the closer the better.
QAs to Stuart's comments on performance, that continues to be a red herring, a programmer's mind set. Allowing a range variable to behave just like a vector does not mean having to expand the APV each time it is used. Using a standard vector requires calculating the addresses of the elements, and that is about the same as calculating a value for an APV. The efficiency of APV processing depends mostly on how well it is implemented, and how much optimization is done.
__________________
� � � � Tom Gutman
Here we're just going to disagree. Confusion already abounds, allowing subscripts on range variables is not going to increase confusion.
The real problem is that vectors and range variables are conceptually the same, regardless of whatever implementation difference are implemented. They both represent sequences of values. That is the user's viewpoint, and it's not going to change. The choices are to try to train users to recognize the implementation differences and restrictions, or to do an implementation that matches the usual concept. I go for the latter, the closer the better.
QAs to Stuart's comments on performance, that continues to be a red herring, a programmer's mind set. Allowing a range variable to behave just like a vector does not mean having to expand the APV each time it is used. Using a standard vector requires calculating the addresses of the elements, and that is about the same as calculating a value for an APV. The efficiency of APV processing depends mostly on how well it is implemented, and how much optimization is done.
__________________
� � � � Tom Gutman
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 8:43:00 PM, Tom_Gutman wrote:
>Here we're just going to
>disagree.
Sort of
> Confusion already
>abounds,
I agree.
>allowing subscripts
>on range variables is not
>going to increase confusion.
I disagree 😉
Richard
>Here we're just going to
>disagree.
Sort of
> Confusion already
>abounds,
I agree.
>allowing subscripts
>on range variables is not
>going to increase confusion.
I disagree 😉
Richard
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 2:15:27 PM, Tom_Gutman wrote:
== The memory issue is irrelevant. That is just a matter of how the implementation chooses to store values. ...
I disagree. A stored short hand form must be expanded at every use. The current range variable form allows the user to trade off space v time; there would need to be some alternative mechanism to allow this control.
== Failing a complete logical identity, I see any commonality as good, a step along the path to what is desired. I have no problem with subscripting range variables
I'm not sure whether I have a problem with it yet - I can't think of anything immediate. Certainly, the potential is why I suggested that the concept needs a bit of thought rather than rejecting it out of hand.
== (although there is a question as to whether such subscripting should be allowed to extrapolate).
That's my main point of consideration. I like the idea of using a range specification just to define the sequence and allow 'out of bounds' values to be calculated (which does help make a case for maintaining the separation between a vector and a range variable). OTOH, there is also a purist view that the bounds shouldn't be exceeded. ... I think I'm happy to let automatic evaluation of a range variable stick to the bounds but allow explicit extra-curricalar activities.
== An obvious next step would be the ability to use submatrix on a range variable. Then, of course, length and last. There are times when salami tactics work.
Yep. As an aside, I'd like to see a subvector function as well as submatrix (or a smart submatrix as well as, or alternatively, smart indexing but I suspect a subvector/smart submatrix is more realistic in the short term).
Stuart
== The memory issue is irrelevant. That is just a matter of how the implementation chooses to store values. ...
I disagree. A stored short hand form must be expanded at every use. The current range variable form allows the user to trade off space v time; there would need to be some alternative mechanism to allow this control.
== Failing a complete logical identity, I see any commonality as good, a step along the path to what is desired. I have no problem with subscripting range variables
I'm not sure whether I have a problem with it yet - I can't think of anything immediate. Certainly, the potential is why I suggested that the concept needs a bit of thought rather than rejecting it out of hand.
== (although there is a question as to whether such subscripting should be allowed to extrapolate).
That's my main point of consideration. I like the idea of using a range specification just to define the sequence and allow 'out of bounds' values to be calculated (which does help make a case for maintaining the separation between a vector and a range variable). OTOH, there is also a purist view that the bounds shouldn't be exceeded. ... I think I'm happy to let automatic evaluation of a range variable stick to the bounds but allow explicit extra-curricalar activities.
== An obvious next step would be the ability to use submatrix on a range variable. Then, of course, length and last. There are times when salami tactics work.
Yep. As an aside, I'd like to see a subvector function as well as submatrix (or a smart submatrix as well as, or alternatively, smart indexing but I suspect a subvector/smart submatrix is more realistic in the short term).
Stuart
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
On 9/10/2009 3:49:25 PM, stuartafbruff wrote:
>Yep. As an aside, I'd like to see a
>subvector function as well as submatrix
>(or a smart submatrix as well as, or
>alternatively, smart indexing but I
>suspect a subvector/smart submatrix is
>more realistic in the short term).
Smart indexing is what's really needed. It's one of the few things I can think of where the concept of a range value would make a lot sense. Anyone could probably figure out what
A[1..4,4..12
means, even without reading the manual.
Richard
>Yep. As an aside, I'd like to see a
>subvector function as well as submatrix
>(or a smart submatrix as well as, or
>alternatively, smart indexing but I
>suspect a subvector/smart submatrix is
>more realistic in the short term).
Smart indexing is what's really needed. It's one of the few things I can think of where the concept of a range value would make a lot sense. Anyone could probably figure out what
A[1..4,4..12
means, even without reading the manual.
Richard
Sep 10, 2009
03:00 AM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Notify Moderator
Sep 10, 2009
03:00 AM
We probably want to take this to a side discussion
😉
On 9/10/2009 11:30:51 AM, rijackson wrote:
>On 9/10/2009 11:20:18 AM, philipoakley
>wrote:
>>Aside:
>>I think vectors which
>>represent the uniform sampling
>>of something along a real
>>world measurement axis (e.g.
>>every 0.1s, or every 2.7kg)
>>should be indexable using that
>>unit of measurement
>>(cardinality to within TOL),
>>so that the sample value at
>>0.3s or sample value at 10.8kg
>>could be accessed.
>
>What's wrong with "match"?
What is wrong is the need to manually manage the
linkage between the location in the data array and
an ancillary vector holding the unit based sample
locations. Your alternative approach is the JMG
approach of disconnection between units and
dimensions and the data values (Ok, so maybe not
that far;-).
>
>> That
>>indexing should be possible
>>using range variables as well.
>
>I disagree. Range variables are not
>vectors: they consist of a start, an
>increment, and a (nominal) end. Indexing
>that is not possible. When you talk
>about indexing a range variable you are
>mentally using the range definition to
>create a vector, and then indexing the
>vector. If that's what you want, then
>you should be using vectors in the first
>place.
>
>Richard
I think you misread/misunderstood what I had tried
to say. It is using the regular A[i where i is a
range variable for iteration across a data set I
meant. Thus both A[0.3s and A[i with
i:0s,0.1s;1.9s would be acceptable, as ways of
accessing the data.
Philip Oakley
😉
On 9/10/2009 11:30:51 AM, rijackson wrote:
>On 9/10/2009 11:20:18 AM, philipoakley
>wrote:
>>Aside:
>>I think vectors which
>>represent the uniform sampling
>>of something along a real
>>world measurement axis (e.g.
>>every 0.1s, or every 2.7kg)
>>should be indexable using that
>>unit of measurement
>>(cardinality to within TOL),
>>so that the sample value at
>>0.3s or sample value at 10.8kg
>>could be accessed.
>
>What's wrong with "match"?
What is wrong is the need to manually manage the
linkage between the location in the data array and
an ancillary vector holding the unit based sample
locations. Your alternative approach is the JMG
approach of disconnection between units and
dimensions and the data values (Ok, so maybe not
that far;-).
>
>> That
>>indexing should be possible
>>using range variables as well.
>
>I disagree. Range variables are not
>vectors: they consist of a start, an
>increment, and a (nominal) end. Indexing
>that is not possible. When you talk
>about indexing a range variable you are
>mentally using the range definition to
>create a vector, and then indexing the
>vector. If that's what you want, then
>you should be using vectors in the first
>place.
>
>Richard
I think you misread/misunderstood what I had tried
to say. It is using the regular A[i where i is a
range variable for iteration across a data set I
meant. Thus both A[0.3s and A[i with
i:0s,0.1s;1.9s would be acceptable, as ways of
accessing the data.
Philip Oakley


{kind=link}
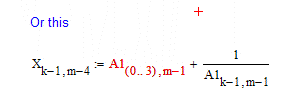{kind=link}